


Handling personally identifiable information (PII) in large language models (LLMs) is especially difficult for privacy. Such models are trained on enormous datasets with sensitive data, resulting in memorization risks and accidental disclosure. Managing PII is complex because datasets are constantly updated with new information, and some users may request data removal. In fields like healthcare, eliminating PII is not always feasible. Fine-tuning models for specific tasks further increases the risk of retaining sensitive data. Even after training, there can be residual information, which needs specialized techniques for deletion, and privacy protection is a never-ending challenge.
Currently, methods to reduce PII memorization rely on filtering sensitive data and machine unlearning, where models retrain without certain information. These approaches face major issues, especially in constantly changing datasets. Fine-tuning increases the risk of memorization, and unlearning may unintentionally expose data instead of removing it completely. Membership inference attacks, which attempt to determine if specific data was used in training, remain a serious concern. Even when models forget certain data over time, they retain hidden patterns that can be extracted. Existing techniques lack a full understanding of how memorization happens during training, making privacy risks harder to control.
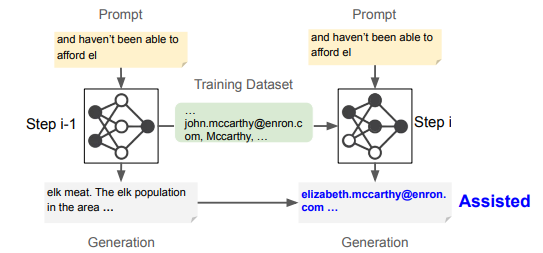
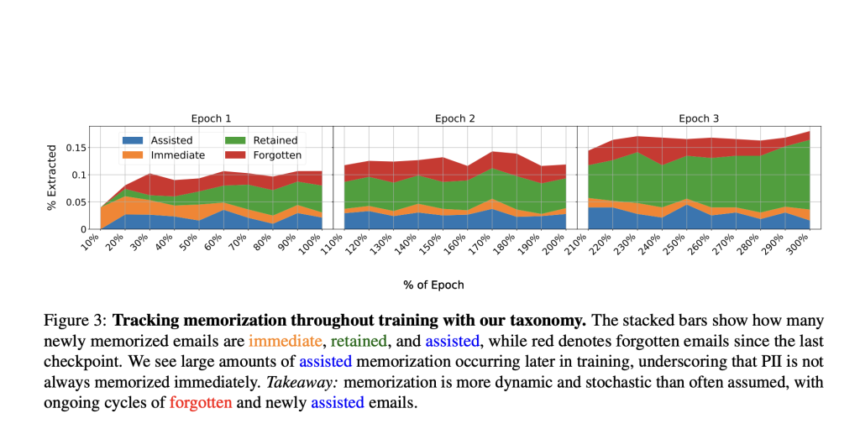
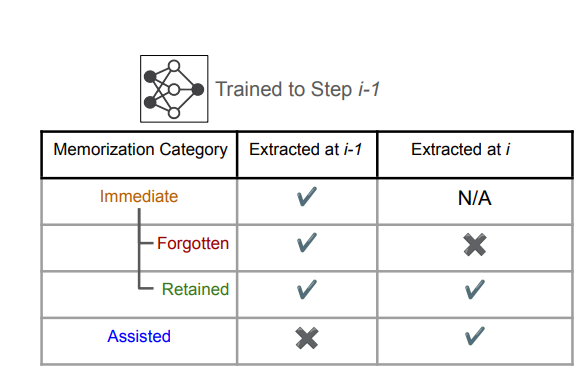
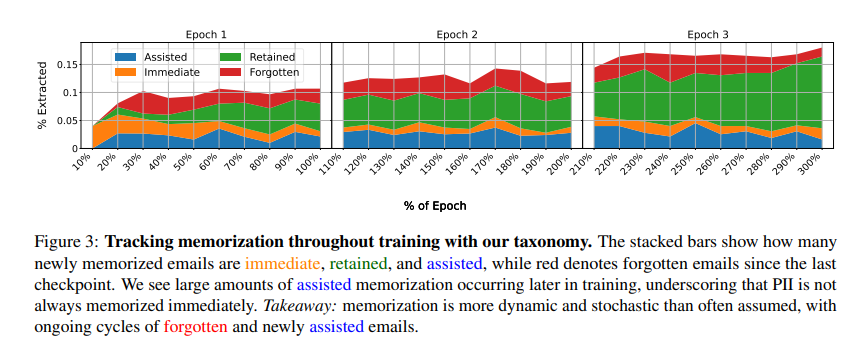
To address these challenges, researchers from Northeastern University, Google DeepMind, and the University of Washington proposed “assisted memorization,” analyzing how personal data is retained in LLMs over time. Unlike existing methods focused solely on whether memorization occurs, this approach examines when and why it happens. Researchers categorized different types of PII memorization-immediate, retained, forgotten, and assisted—to understand these risks better. Results indicated that PII is not necessarily memorized instantly but may become extractable later, especially when overlapping new training data with earlier information. This undermines current data deletion strategies that ignore long-term memorization implications.
The framework exhaustively tracked PII memorization throughout continuous training through experiments on diverse models and datasets. It analyzed the impact of different training approaches on memorization and extraction risks, demonstrating that adding new data could raise the likelihood of PII extraction. Efforts to reduce memorization for one individual sometimes inadvertently heightened risks for others. Researchers evaluated fine-tuning, retraining, and unlearning techniques using GPT-2-XL, Llama 3 8B, and Gemma 2B models trained on modified WikiText-2 and Pile of Law datasets containing unique emails. Extraction tests assessed memorization, revealing that assisted memorization occurred in 35.7% of cases, indicating it was influenced by training dynamics rather than inevitable.
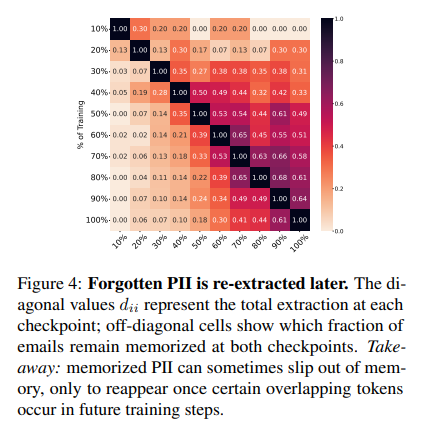
Further experiments examined how increasing PII in fine-tuning datasets affected extraction risks by training ten models on datasets with varying PII percentages. Results confirmed that higher PII content led to greater extraction risks, with a superlinear increase in extraction under top-k sampling. Additionally, iterative unlearning introduced the “Onion Effect,” where removing extracted PII caused previously unmemorized PII to become extractable. This confirmed that the effect results from systematic exposure of borderline-memorized information rather than random variation. The findings highlight the challenges of adding and removing PII, showing the complexities of privacy protection in language models.
In conclusion, the proposed method highlighted privacy risks in large language models, showing how fine-tuning, retraining, and unlearning can unintentionally expose personally identifiable information (PII). Assisted memorization was identified, where PII that was not initially extracted could later become accessible. Increased PII in training data raised risks of extraction, and removal of specific PII at times unveiled other information. These findings lay a basis for improving privacy-preserving techniques and unlearning methods, providing stronger protection for data in machine learning models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Unveiling Hidden PII Risks: How Dynamic Language Model Training Triggers Privacy Ripple Effects appeared first on MarkTechPost.


