


Deep neural networks’ seemingly anomalous generalization behaviors, benign overfitting, double descent, and successful overparametrization are neither unique to neural networks nor inherently mysterious. These phenomena can be understood through established frameworks like PAC-Bayes and countable hypothesis bounds. A researcher from New York University presents “soft inductive biases” as a key unifying principle in explaining these phenomena: rather than restricting hypothesis space, this approach embraces flexibility while maintaining a preference for simpler solutions consistent with data. This principle applies across various model classes, showing that deep learning isn’t fundamentally different from other approaches. However, deep learning remains distinctive in specific aspects.
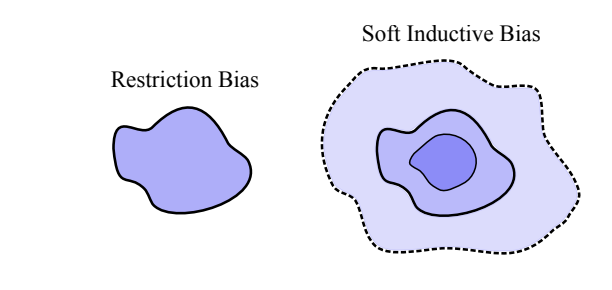
Inductive biases traditionally function as restriction biases that constrain hypothesis space to improve generalization, allowing data to eliminate inappropriate solutions. Convolutional neural networks exemplify this approach by imposing hard constraints like locality and translation equivariance on MLPs through parameter removal and sharing. Soft inductive biases represent a broader principle where certain solutions are preferred without eliminating alternatives that fit the data equally well. Unlike restriction biases with their hard constraints, soft biases guide rather than limit the hypothesis space. These biases influence the training process through mechanisms like regularization and Bayesian priors over parameters.
Embracing flexible hypothesis spaces has complex real-world data structures but requires prior bias toward certain solutions to ensure good generalization. Despite challenging conventional wisdom around overfitting and metrics like Rademacher complexity, phenomena like overparametrization align with the intuitive understanding of generalization. These phenomena can be characterized through long-established frameworks, including PAC-Bayes and countable hypothesis bounds. The concept of effective dimensionality provides additional intuition for understanding behaviors. Frameworks that have shaped conventional generalization wisdom often fail to explain these phenomena, highlighting the value of established alternative methods for understanding modern machine learning‘s generalization properties.
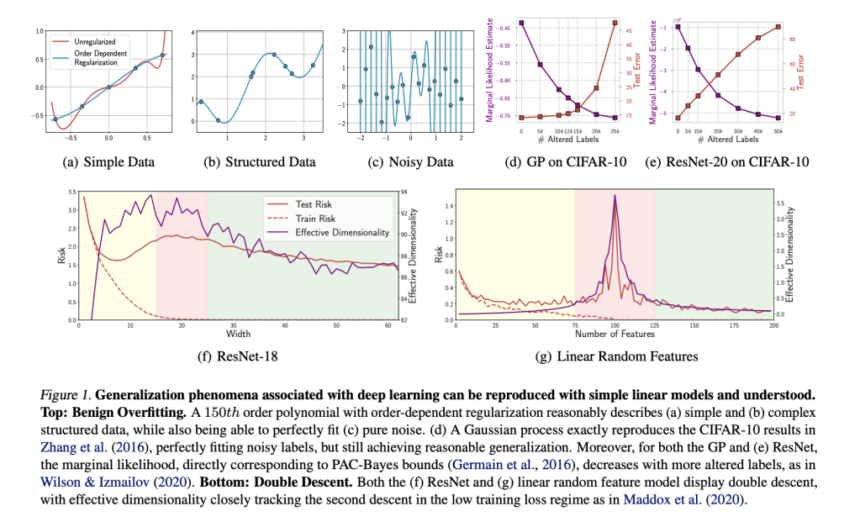
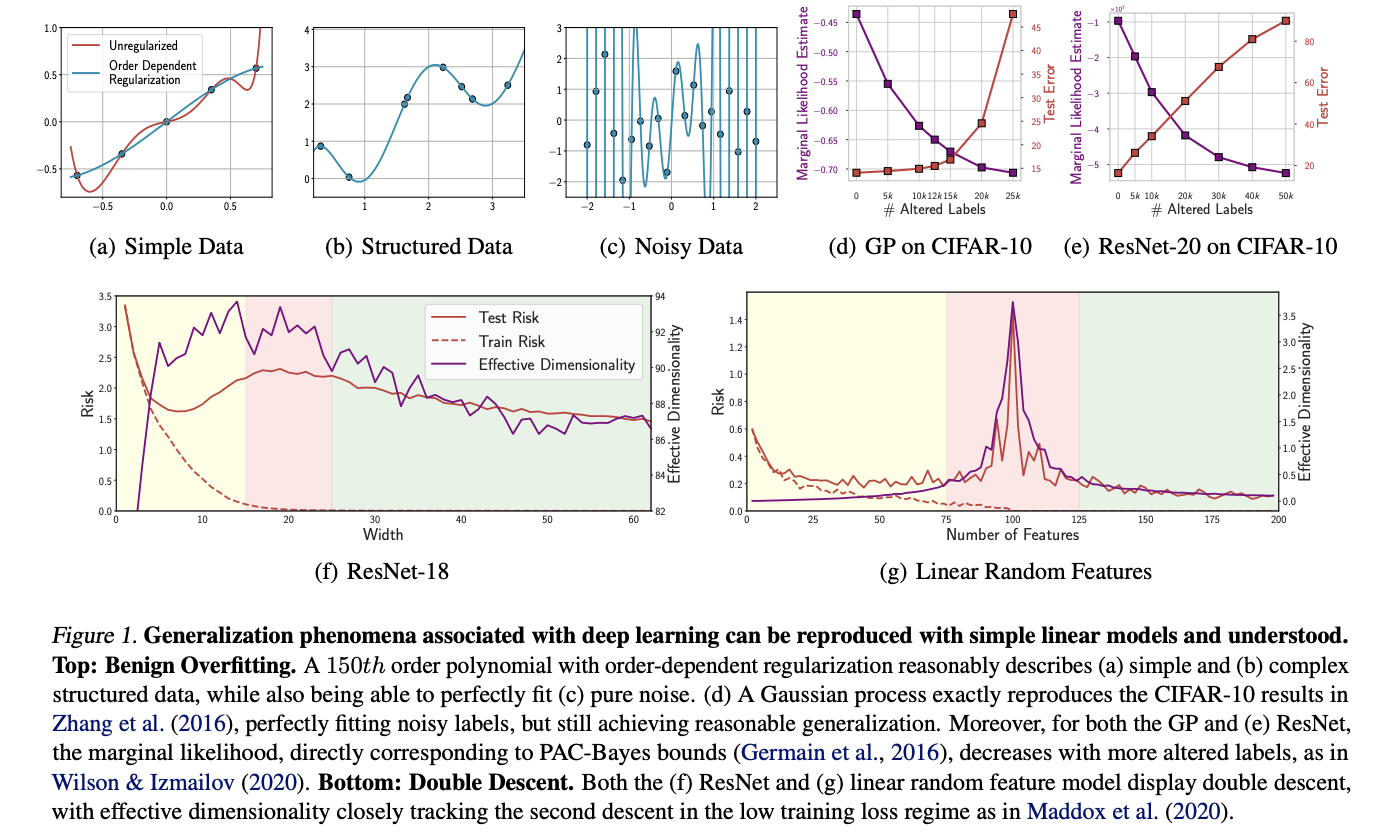
Benign overfitting describes models’ ability to perfectly fit noise while still generalizing well on structured data, showing that capacity for overfitting doesn’t necessarily lead to poor generalization on meaningful problems. Convolutional neural networks could fit random image labels while maintaining strong performance on structured image recognition tasks. This behavior contradicts established generalization frameworks like VC dimension and Rademacher complexity, with the authors claiming no existing formal measure could explain these models’ simplicity despite their enormous size. Another definition for benign overfitting is described as “one of the key mysteries uncovered by deep learning.” However, this isn’t unique to neural networks, as it can be reproduced across various model classes.
Double descent refers to a generalization error that decreases, increases, and then decreases again as model parameters increase. The initial pattern follows the “classical regime” where models capture useful structure but eventually overfit. The second descent occurs in the “modern interpolating regime” after training loss approaches zero. Double descent is shown for a ResNet-18 and a linear model. For the ResNet, cross-entropy loss is seen on CIFAR-100 as the width of each layer increases. As layer width increases in the ResNet or parameters increase in the linear model, both follow similar patterns: Effective dimensionality rises until it reaches the interpolation threshold, then decreases as generalization improves. This phenomenon can be formally tracked using PAC-Bayes bounds.
In conclusion, Overparametrization, benign overfitting, and double descent represent intriguing phenomena deserving continued study. However, contrary to widespread beliefs, these behaviors align with established generalization frameworks, can be reproduced in non-neural models, and can be intuitively understood. This understanding should bridge diverse research communities, preventing valuable perspectives and frameworks from being overlooked. Other phenomena like grokking and scaling laws aren’t presented as evidence for rethinking generalization frameworks or as neural network-specific. Recent research confirms that these phenomena apply to linear models. Moreover, PAC-Bayes and countable hypothesis bounds remain consistent with large language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.


 It’s operated using an easy-to-use CLI
It’s operated using an easy-to-use CLI  and native client SDKs in Python and TypeScript
and native client SDKs in Python and TypeScript  .
.The post Understanding Generalization in Deep Learning: Beyond the Mysteries appeared first on MarkTechPost.


