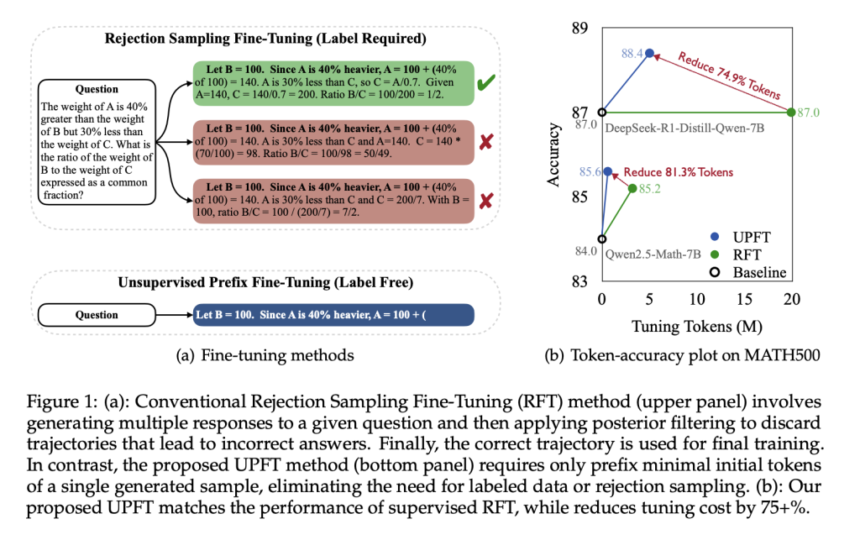


Unleashing a more efficient approach to fine-tuning reasoning in large language models, recent work by researchers at Tencent AI Lab and The Chinese University of Hong Kong introduces Unsupervised Prefix Fine-Tuning (UPFT). This method refines a model’s reasoning abilities by focusing solely on the first 8 to 32 tokens of its generated responses, rather than processing complete solution trajectories. By doing so, UPFT aims to capture the critical early steps of reasoning that are common across multiple solution paths while significantly reducing computational overhead.
Large language models have excelled in tasks such as language understanding and generation, yet enhancing their reasoning capabilities remains a complex challenge. Traditional fine-tuning techniques rely on either large amounts of annotated data or on procedures that generate multiple complete responses and then filter out errors through rejection sampling. These conventional methods are both resource intensive and dependent on the availability of reliable, labeled data. Moreover, extensive processing of full-length responses may include redundant information; the most informative content for reasoning appears in the early stages of the model’s output. Recognizing this, UPFT narrows the focus to the initial tokens—the part where reasoning begins and common structural elements emerge—thus addressing both efficiency and the dependence on expensive supervision.

Introducing Unsupervised Prefix Fine-Tuning
The work begins with an observation termed Prefix Self-Consistency. It was noted that, across various solution trajectories generated for the same problem, the initial reasoning steps tend to be remarkably similar. These early tokens often provide a shared foundation, even when later parts of the reasoning diverge. UPFT builds on this insight by training models using only these minimal prefixes. The method eliminates the need for detailed annotations or for generating and filtering multiple full responses, allowing the model to focus on establishing a robust reasoning framework early on. In essence, UPFT leverages the naturally occurring consistency in the model’s first few tokens to guide its learning process.
Technical Details and Advantages
At its core, UPFT reframes the training process using principles from Bayesian reasoning. Instead of considering entire reasoning traces, the method breaks down the probability of arriving at a correct answer into two components: coverage and accuracy. Coverage refers to the range of possible reasoning paths that stem from a given prefix, while accuracy indicates the likelihood that, once a particular prefix is established, the remaining tokens will lead to a correct answer. By training on these early tokens, UPFT maximizes the benefits of both elements, striking a balance between exploring diverse reasoning approaches and ensuring reliable outcomes.
Practically, this method offers clear benefits. Focusing on the prefix significantly reduces the amount of token data needed during training. Empirical studies suggest that UPFT can cut the number of tokens processed by up to 95% compared to full-token approaches. Furthermore, by dispensing with the need for rejection sampling, the method simplifies the training pipeline, reducing both time and memory requirements. This approach is particularly appealing for applications where computational resources are limited or where large labeled datasets are not available.

Empirical Insights and Data
The performance of UPFT has been evaluated across several established reasoning benchmarks, including GSM8K, MATH500, AIME2024, and GPQA. In these tests, models fine-tuned with UPFT performed comparably to those trained using conventional, more resource-intensive methods. For instance, when applied to the Qwen2.5-Math-7B-Instruct model, UPFT achieved an improvement in average accuracy while using significantly fewer tokens during both training and inference. On benchmarks that demand complex reasoning, such as AIME2024, the method demonstrated a marked enhancement in performance, suggesting that early reasoning steps contain the essential cues needed for problem-solving.
Additionally, UPFT’s efficiency in reducing computational costs is noteworthy. By working with substantially shorter token sequences, the training process becomes faster and less demanding on hardware, which could be particularly beneficial in scenarios where quick deployment or lower energy consumption is a priority.
Conclusion
The introduction of Unsupervised Prefix Fine-Tuning represents a thoughtful step toward more efficient and accessible methods for enhancing reasoning in large language models. By concentrating on the initial tokens—those that encapsulate the core of the reasoning process—this approach reduces the need for extensive labeled datasets and complex sampling strategies. Rather than relying on large-scale annotations or rejection sampling to correct errors later in the reasoning process, UPFT refines models by focusing on the parts of the response that are both consistent and informative.
In reflecting on the necessity of expensive labeled data and rejection sampling, UPFT suggests a more streamlined alternative. It offers a method where a minimal, unsupervised fine-tuning process can yield significant improvements in reasoning performance. This refined approach not only makes the process more resource efficient but also opens the door to developing self-improving reasoning models in a more accessible manner, challenging some of the conventional assumptions about what is required for effective model training.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Tencent AI Lab Introduces Unsupervised Prefix Fine-Tuning (UPFT): An Efficient Method that Trains Models on only the First 8-32 Tokens of Single Self-Generated Solutions appeared first on MarkTechPost.