

Advances in large language and multimodal speech-text models have laid a foundation for seamless, real-time, natural, and human-like voice interactions. Achieving this requires systems to process speech content, emotional tones, and audio cues while giving accurate and coherent responses. However, challenges remain in overcoming differences in speech and text sequences, limited pre-training for speech tasks and preserving knowledge in the language model. The system cannot also fill gaps in functions such as speech translation, emotion recognition, and simultaneous processing during a conversation.
Currently, voice interaction systems are divided into native and aligned multimodal models. Native multimodal models integrate both speech and text understanding and generation. However, they face challenges with longer speech token sequences than text sequences, making them inefficient as model sizes grow. These models also struggle with limited speech data, leading to issues like catastrophic forgetting. Aligned multimodal models aim to combine voice capabilities with pre-trained text models. However, these are trained on small datasets and lack focus on complex speech tasks like emotion recognition or speaker analysis. Besides, these models have not been properly evaluated to handle different speaking styles or full-duplex conversation, essential for seamless voice interactions.
To mitigate the issues with current multimodal models, researchers from Tongyi Lab and Alibaba Group proposed MinMo, a new multimodal large language model designed to improve voice comprehension and generation. The researcher trained the model on over 1.4 million hours of speech data across various tasks like Speech-to-Text, Text-to-Speech, and Speech-to-Speech. This extensive training allows MinMo to achieve state-of-the-art performance on multiple benchmarks while preventing catastrophic forgetting of text LLM capabilities. Unlike previous models, MinMo integrates speech and text seamlessly without losing performance on text tasks and enhances voice interaction capabilities like emotion recognition, speaker analysis, and multilingual speech recognition.

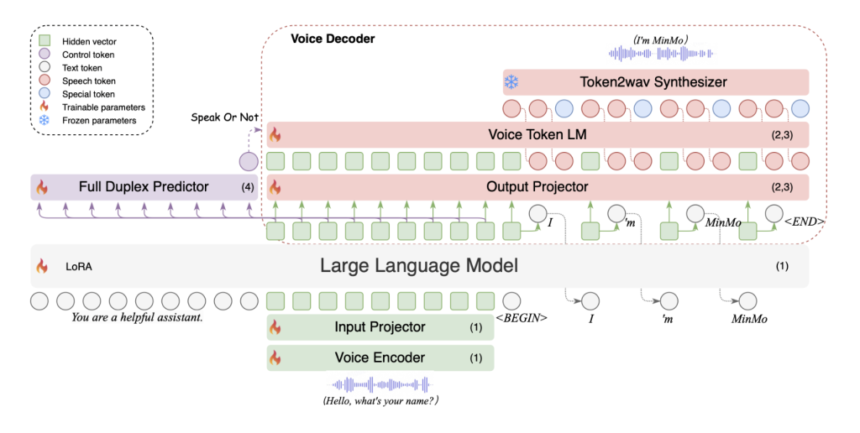
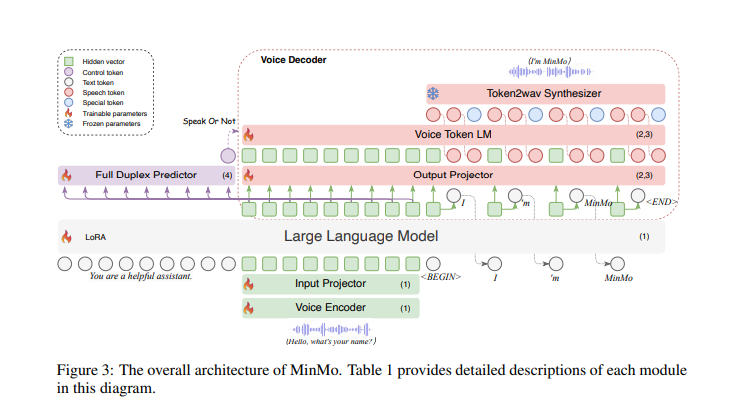
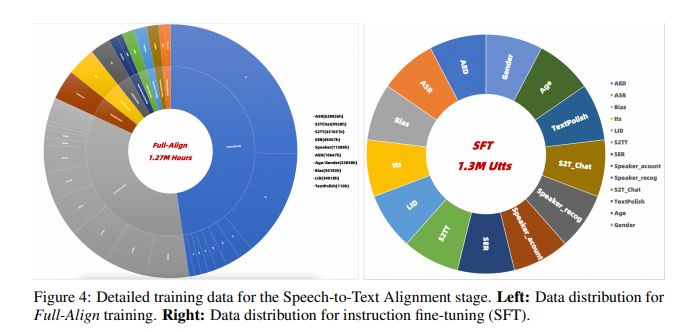
Researchers designed MinMo with a multi-stage training approach to align speech and text modalities, enabling speech-to-text, text-to-speech, speech-to-speech, and duplex interactions. The model leverages a pretrained text LLM and includes core components like the SenseVoice-large voice encoder for multilingual speech and emotion recognition, the Qwen2.5-7B-instruct LLM for text processing, and CosyVoice 2 for efficient audio generation. MinMo also introduces an AR streaming Transformer voice decoder, which enhances performance and reduces latency. With around 8 billion parameters, the model provided real-time response and full-duplex interaction with a latency of about 600 ms.
The researchers tested MinMo across various benchmarks, including multilingual speech recognition, speech-to-text enhancement, and voice generation. The results showed that MinMo outperformed most models, including Whisper Large v3, particularly in multilingual speech recognition tasks, and achieved state-of-the-art performance in multilingual speech translation. It also excelled in speech-to-text enhancement, speech emotion recognition (SER), and audio event understanding. MinMo achieved 85.3% accuracy in language identification using Fleur’s dataset, surpassing all previous models. In tasks such as gender detection, age estimation, and punctuation insertion, MinMo demonstrated strong performance, outpacing models like Qwen2.5-7B and SenseVoice-L. It also showed superior performance in dialect and role-playing tasks in voice generation, with an accuracy of 98.4%, compared to GLM-4-Voice’s 63.1%. Despite declining performance in speech-to-speech tasks due to complexity, MinMo performed well in conversational tasks and logical reasoning. The model achieved high sensitivity in turn-taking with around 99% prediction performance and a response latency of about 600ms in full-duplex interactions.
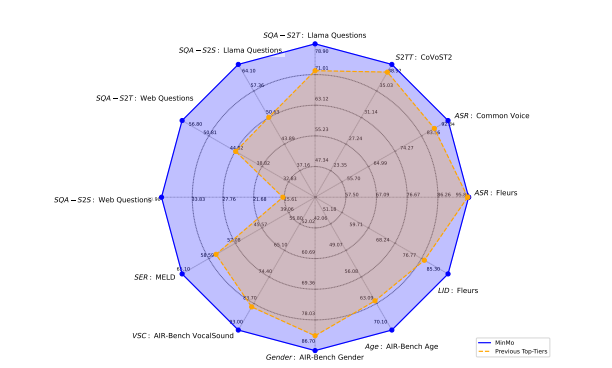

In conclusion, the proposed MinMo model advances voice interaction systems by addressing challenges like sequence length discrepancies and catastrophic forgetting. Its multi-stage alignment strategy and voice decoder enable multilingual speech and emotion recognition performance. MinMo sets a new benchmark for natural voice interactions and can act as a baseline for future research, with potential improvements in instruction-following and end-to-end audio generation. Future advancements could focus on refining pronunciation handling and developing fully integrated systems.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
The post MinMo: A Multimodal Large Language Model with Approximately 8B Parameters for Seamless Voice Interaction appeared first on MarkTechPost.