


The rapid advancement of Large Language Models (LLMs) has significantly improved their ability to generate long-form responses. However, evaluating these responses efficiently and fairly remains a critical challenge. Traditionally, human evaluation has been the gold standard, but it is costly, time-consuming, and prone to bias. To mitigate these limitations, the LLM-as-a-Judge paradigm has emerged, leveraging LLMs themselves to act as evaluators. Despite this advancement, LLM-as-a-Judge models face two significant challenges: (1) a lack of human-annotated Chain-of-Thought (CoT) rationales, which are essential for structured and transparent evaluation, and (2) existing approaches that rely on rigid, hand-designed evaluation components, making them difficult to generalize across different tasks and domains. These constraints limit the accuracy and robustness of AI-based evaluation models. To overcome these issues, Meta AI has introduced EvalPlanner, a novel approach designed to improve the reasoning and decision-making capabilities of LLM-based judges through an optimized planning-execution strategy.
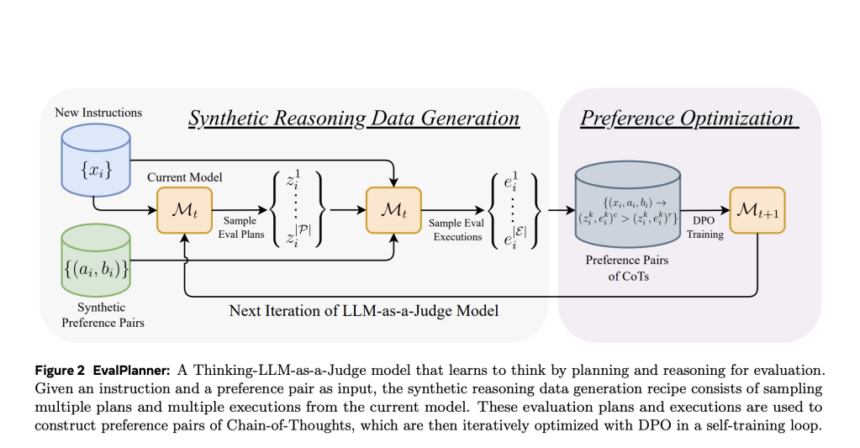
EvalPlanner is a preference optimization algorithm specifically designed for Thinking-LLM-as-a-Judge models. EvalPlanner differentiates itself by employing a three-stage evaluation process: (1) generation of an unconstrained evaluation plan, (2) execution of the plan, and (3) final judgment. Unlike previous methods, EvalPlanner does not constrain reasoning traces to predefined rubrics or criteria. Instead, it generates flexible evaluation plans that adapt to various domains and task requirements. The system operates in a self-training loop, iteratively refining evaluation plans and execution strategies using synthetically generated preference pairs. By continuously optimizing itself, EvalPlanner ensures more reliable, transparent, and scalable evaluations compared to existing LLM-as-a-Judge models.
The innovation behind EvalPlanner lies in its structured reasoning approach, which separates the planning phase from the execution phase. In the planning stage, the model formulates a detailed evaluation roadmap tailored to the specific instruction at hand. During execution, the model follows the step-by-step plan to assess and compare responses systematically. This two-step separation enables better alignment between evaluation goals and reasoning processes, leading to more accurate and explainable judgments.

Technical Details and Benefits of EvalPlanner
EvalPlanner introduces a self-training mechanism that continuously refines both the planning and execution components of the evaluation process. The model leverages Direct Preference Optimization (DPO) to iteratively improve its judgments by learning from synthetic preference pairs. These preference pairs are derived by sampling multiple evaluation plans and executions, allowing EvalPlanner to identify the most effective reasoning patterns.
The primary benefits of EvalPlanner include:
- Increased Accuracy: By generating unconstrained evaluation plans, EvalPlanner significantly reduces bias and improves judgment consistency across different tasks.
- Scalability: Unlike manually crafted evaluation rubrics, EvalPlanner automatically adapts to new evaluation tasks, making it a highly scalable solution.
- Efficiency: EvalPlanner achieves state-of-the-art (SOTA) performance on various benchmarks with fewer training examples, relying only on synthetic preference pairs rather than extensive human annotations.
- Transparency: By explicitly separating planning from execution, EvalPlanner enhances the interpretability of its reasoning process, making it easier to analyze and debug.
Experimental Results and Performance Insights
Meta AI evaluated EvalPlanner across multiple reward modeling benchmarks, including RewardBench, RM-Bench, JudgeBench, and FollowBenchEval. The results demonstrate EvalPlanner’s superior performance in evaluating complex, multi-level constraints and improving over existing models in various domains, such as chat-based interactions, safety evaluation, coding, and mathematical reasoning.
- State-of-the-Art Results on RewardBench: EvalPlanner achieved a score of 93.9, outperforming leading models that rely on 30 times more human-annotated data. This highlights the effectiveness of EvalPlanner’s synthetic data-driven training methodology.
- Improved Robustness on RM-Bench: EvalPlanner demonstrated 8% higher accuracy compared to previous SOTA models in handling nuanced evaluation criteria, showcasing its ability to resist subtle biases and variations in response quality.
- Superior Constraint Handling in FollowBenchEval: For multi-level constraints evaluation, EvalPlanner outperformed competitive baselines by 13%, emphasizing its ability to effectively plan and reason through complex prompts.
- Generalization to JudgeBench: EvalPlanner demonstrated strong generalization capabilities, achieving comparable performance to larger models trained on extensive human-annotated datasets while using significantly fewer preference pairs.
Additionally, ablation studies confirmed that iterative optimization of evaluation plans significantly enhances performance. When trained with as few as 5K synthetic preference pairs, EvalPlanner maintained competitive performance, demonstrating its data efficiency compared to traditional models.

Conclusion: The Future of AI-Based Evaluation
EvalPlanner represents a major breakthrough in the development of AI-based evaluation frameworks. By combining preference optimization, structured planning, and self-training, it effectively addresses the limitations of existing LLM-as-a-Judge models. Its scalability, accuracy, and transparency make it a promising tool for automated, unbiased, and efficient evaluation of AI-generated responses across diverse applications. As AI models continue to evolve, EvalPlanner paves the way for more reliable and interpretable evaluation systems, ultimately enhancing trust and fairness in AI-driven decision-making. Future research can explore extending EvalPlanner’s capabilities to reward modeling in Reinforcement Learning with Human Feedback (RLHF) pipelines and integrating it into real-world AI auditing frameworks.
With EvalPlanner, Meta AI has set a new standard in the field of AI evaluation, demonstrating that teaching AI to plan and reason can significantly improve judgment quality. This advancement is a crucial step toward autonomous and scalable AI governance, ensuring that future AI systems operate with greater precision, fairness, and accountability.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.
 Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
The post Meta AI Proposes EvalPlanner: A Preference Optimization Algorithm for Thinking-LLM-as-a-Judge appeared first on MarkTechPost.


