


The dominant approach to pretraining large language models (LLMs) relies on next-token prediction, which has proven effective in capturing linguistic patterns. However, this method comes with notable limitations. Language tokens often convey surface-level information, requiring models to process vast amounts of data to develop deeper reasoning capabilities. Additionally, token-based learning struggles with capturing long-term dependencies, making tasks that require planning and abstraction more difficult. Researchers have explored alternative strategies, such as knowledge distillation and structured input augmentation, but these approaches have not fully addressed the limitations of token-based learning. This raises an important question: Can LLMs be trained in a way that combines token-level processing with conceptual understanding? Meta AI introduces Continuous Concept Mixing (CoCoMix) as a potential solution.
CoCoMix: A Different Approach to Pretraining
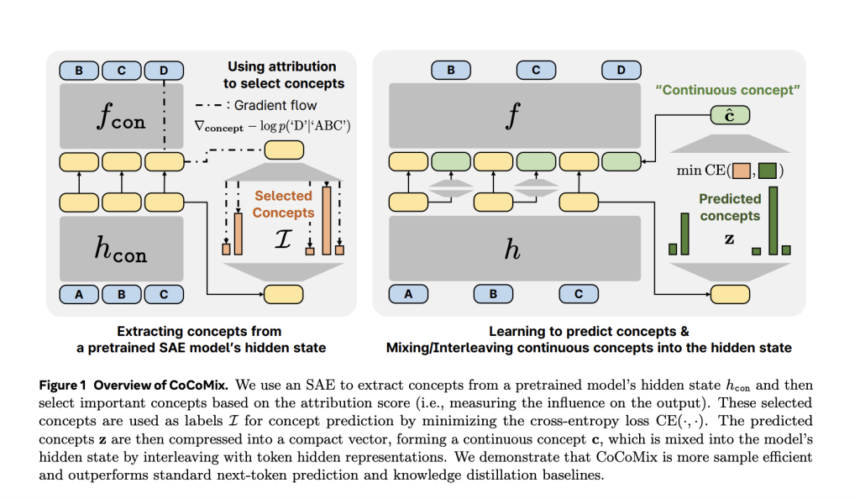
CoCoMix integrates token prediction with the modeling of continuous concepts derived from hidden states of a pretrained model. The method employs a Sparse Autoencoder (SAE) to extract high-level semantic representations, which are then incorporated into the training process by interleaving them with token embeddings. This design allows the model to maintain the benefits of token-based learning while enhancing its ability to recognize and process broader conceptual structures. By enriching the token-based paradigm with concept-level information, CoCoMix aims to improve reasoning efficiency and model interpretability.

Technical Details and Benefits
CoCoMix operates through three main components:
- Concept Extraction via Sparse Autoencoders (SAEs): A pretrained SAE identifies latent semantic features from a model’s hidden states, capturing information that extends beyond individual tokens.
- Concept Selection with Attribution Scoring: Not all extracted concepts contribute equally to predictions. CoCoMix employs attribution methods to determine which concepts are most influential and should be retained.
- Interleaving Continuous Concepts with Token Representations: The selected concepts are compressed into a continuous vector and integrated into the hidden states alongside token embeddings, allowing the model to utilize both token-level and conceptual information.
This approach improves sample efficiency, enabling models to achieve comparable performance with fewer training tokens. Additionally, CoCoMix enhances interpretability by making it possible to inspect and adjust the extracted concepts, offering a clearer view of how the model processes information.

Performance and Evaluation
Meta AI evaluated CoCoMix across multiple benchmarks, including OpenWebText, LAMBADA, WikiText-103, HellaSwag, PIQA, SIQA, Arc-Easy, and WinoGrande. The findings indicate:
- Improved Sample Efficiency: CoCoMix matches the performance of next-token prediction while requiring 21.5% fewer training tokens.
- Enhanced Generalization: Across various model sizes (69M, 386M, and 1.38B parameters), CoCoMix demonstrated consistent improvements in downstream task performance.
- Effective Knowledge Transfer: CoCoMix supports knowledge transfer from smaller models to larger ones, outperforming traditional knowledge distillation techniques.
- Greater Interpretability: The integration of continuous concepts allows for greater control and transparency in model decision-making, providing a clearer understanding of its internal processes.

Conclusion
CoCoMix presents an alternative approach to LLM pretraining by combining token prediction with concept-based reasoning. By incorporating structured representations extracted via SAEs, CoCoMix enhances efficiency and interpretability without disrupting the underlying next-token prediction framework. Experimental results suggest that this method provides a balanced way to improve language model training, particularly in areas requiring structured reasoning and transparent decision-making. Future research may focus on refining concept extraction methods and further integrating continuous representations into pretraining workflows.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post Meta AI Introduces CoCoMix: A Pretraining Framework Integrating Token Prediction with Continuous Concepts appeared first on MarkTechPost.


