



Large language models (LLMs) have become central to natural language processing (NLP), excelling in tasks such as text generation, comprehension, and reasoning. However, their ability to handle longer input sequences is limited by significant computational challenges, particularly memory overhead during inference caused by key-value (KV) caches. Since memory requirements scale linearly with sequence length, this limits the maximum context window that models can effectively process. Existing solutions, such as sparse attention mechanisms and off-chip storage, attempt to mitigate this issue but often introduce trade-offs, such as increased latency or the risk of losing important information. Addressing memory consumption without compromising model performance remains a critical challenge in scaling LLMs for practical applications.
A team of researchers from Tsinghua University, Shanghai Qi Zhi Institute, UCLA, and TapTap have introduced Tensor Product Attention (TPA), an attention mechanism designed to alleviate the KV cache bottleneck. TPA leverages tensor decompositions to represent queries, keys, and values (QKV) compactly, significantly reducing the KV cache size during inference. By employing contextual low-rank factorization, TPA achieves substantial memory savings while maintaining or improving model performance. Moreover, it integrates seamlessly with Rotary Position Embedding (RoPE), allowing compatibility with widely-used attention-based architectures like LLaMA. This approach enables TPA to serve as a drop-in replacement for multi-head attention (MHA), forming the basis of the Tensor Product Attention Transformer (T6), a sequence modeling architecture that shows notable performance improvements in language modeling tasks.

Technical Details and Benefits
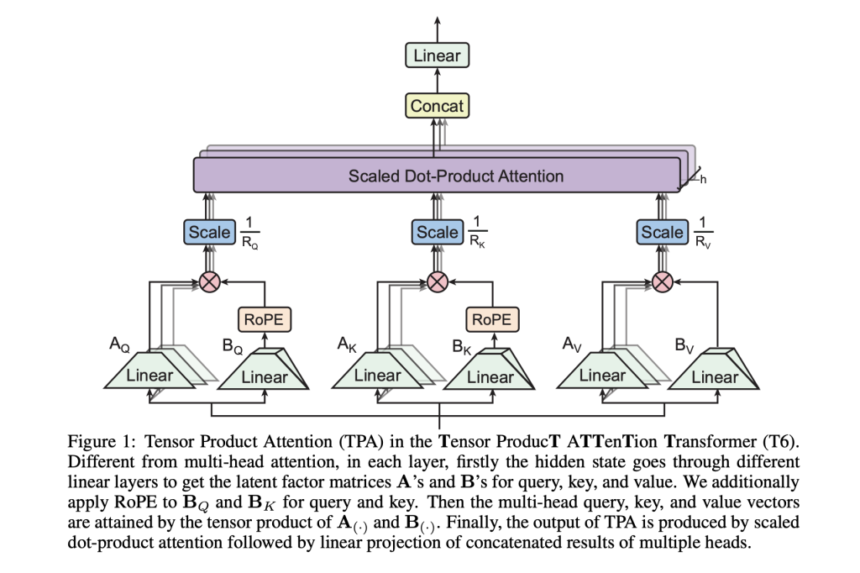
TPA introduces a novel approach to factorizing QKV activations dynamically into low-rank components. Unlike static weight factorization techniques like LoRA, TPA generates contextual representations tailored to the input data. Each token’s Q, K, and V components are expressed as a sum of tensor products of latent factors, which are derived through linear projections of the token’s hidden state. This tensor structure facilitates efficient representation and reduces memory usage.
A key advantage of TPA is its integration with RoPE. Traditional low-rank methods face challenges with RoPE due to its dependence on relative positional invariance. TPA resolves this by pre-rotating tensor components, enabling efficient caching and inference while preserving positional information.
The memory efficiency of TPA is significant. Standard MHA relies on a full-size KV cache proportional to the number of heads and their dimensions, whereas TPA reduces this requirement by caching only the factorized components. This reduction enables the processing of much longer sequences within the same memory constraints, making it particularly effective for applications requiring extended context windows.
Results and Insights
The researchers evaluated TPA on the FineWeb-Edu100B dataset across various language modeling tasks. The Tensor Product Attention Transformer (T6) consistently outperformed baselines, including MHA, Multi-Query Attention (MQA), Grouped Query Attention (GQA), and Multi-head Latent Attention (MLA).
In terms of training and validation loss, TPA demonstrated faster convergence and lower final losses compared to its counterparts. For example, in experiments with large-scale models (773M parameters), TPA achieved significantly lower validation losses than MLA and GQA. Additionally, TPA showed superior perplexity results across multiple configurations, highlighting its efficiency and accuracy.
Beyond pretraining metrics, TPA performed exceptionally well in downstream tasks such as ARC, BoolQ, HellaSwag, and MMLU. On zero-shot and two-shot prompts, TPA consistently ranked among the best-performing methods, achieving average accuracies of 51.41% and 53.12%, respectively, for medium-sized models. These findings emphasize TPA’s capability to generalize across diverse language tasks effectively.

Conclusion
Tensor Product Attention (TPA) addresses the scalability challenges of large language models by introducing a dynamic, low-rank factorization mechanism that reduces the memory footprint of KV caches while maintaining strong performance. Its compatibility with existing architectures and solid results across various benchmarks make it a practical alternative to traditional attention mechanisms. As the need for longer context processing grows in language models, methods like TPA provide an efficient path forward, combining memory efficiency with robust performance for real-world applications.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
The post Meet Tensor Product Attention (TPA): Revolutionizing Memory Efficiency in Language Models appeared first on MarkTechPost.


