



The development of large language models (LLMs) has significantly advanced artificial intelligence (AI) across various fields. Among these advancements, mobile GUI agents—designed to perform tasks autonomously on smartphones—show considerable potential. However, evaluating these agents poses notable challenges. Current datasets and benchmarks often rely on static frame evaluations, which provide snapshots of app interfaces for agents to predict the next action. This method falls short of simulating the dynamic and interactive nature of real-world mobile tasks, creating a gap between tested capabilities and actual performance. Additionally, existing platforms tend to restrict app diversity, task complexity, and real-time interaction, underscoring the need for a more comprehensive evaluation framework.
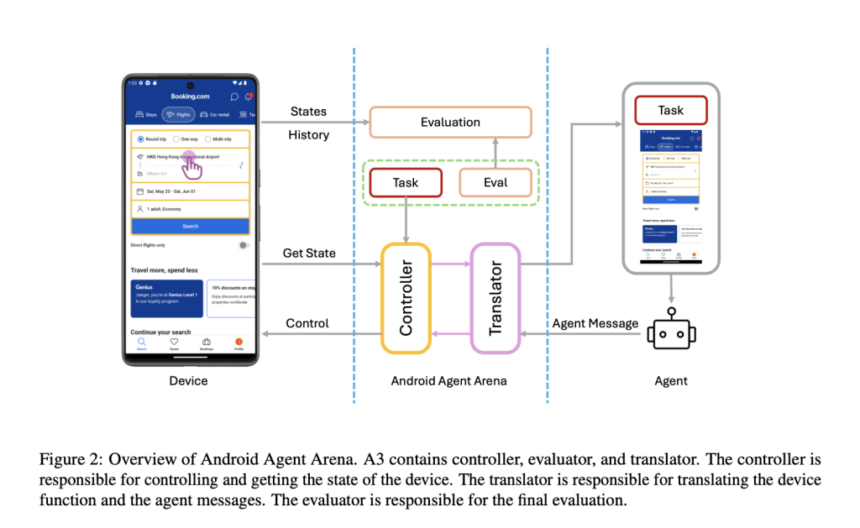
In response to these challenges, researchers from CUHK, vivo AI Lab, and Shanghai Jiao Tong University have introduced the Android Agent Arena (A3), a platform designed to improve the evaluation of mobile GUI agents. A3 provides a dynamic evaluation environment with tasks that mirror real-world scenarios. The platform integrates 21 commonly used third-party apps and includes 201 tasks ranging from retrieving online information to completing multi-step operations. Additionally, A3 incorporates an automated evaluation system leveraging business-level LLMs, which reduces the need for manual intervention and coding expertise. This approach aims to close the gap between research-driven development and practical applications for mobile agents.

Key Features and Advantages of A3
A3 is built on the Appium framework, facilitating seamless interaction between GUI agents and Android devices. It supports a broad action space, ensuring compatibility with agents trained on diverse datasets. Tasks are categorized into three types—operation tasks, single-frame queries, and multi-frame queries—and are divided into three levels of difficulty. This variety enables a thorough assessment of an agent’s capabilities, from basic navigation to complex decision-making.
The platform’s evaluation mechanism includes task-specific functions and a business-level LLM evaluation process. Task-specific functions use predefined criteria to measure performance, while the LLM evaluation process employs models like GPT-4o and Gemini for autonomous assessment. This combination ensures accurate evaluations and scalability for a growing number of tasks.

Insights from Initial Testing
The researchers tested various agents on A3, including fine-tuned models and business-level LLMs, yielding the following insights:
- Challenges in Dynamic Evaluations: While agents performed well in static evaluations, they faced difficulties in A3’s dynamic environment. For instance, tasks requiring multi-frame queries often resulted in low success rates, highlighting the challenges of real-world scenarios.
- Role of LLMs in Evaluation: The LLM-based evaluation achieved 80–84% accuracy, with cross-validation reducing errors significantly. However, complex tasks occasionally required human oversight to ensure accuracy.
- Common Errors: Observed errors included incorrect click coordinates, redundant actions, and difficulties in self-correction. These issues underscore the need for agents capable of learning adaptively and understanding context.

Conclusion
Android Agent Arena (A3) offers a valuable framework for evaluating mobile GUI agents. By providing a diverse set of tasks, an extensive action space, and automated evaluation systems, A3 addresses many limitations of existing benchmarks. The platform represents a step forward in aligning research advancements with practical applications, enabling the development of more capable and reliable AI agents. As AI continues to evolve, A3 sets a strong foundation for future innovations in mobile agent evaluation.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post Meet Android Agent Arena (A3): A Comprehensive and Autonomous Online Evaluation System for GUI Agents appeared first on MarkTechPost.

