

LLMs have exhibited impressive capabilities through extensive pretraining and alignment techniques. However, while they excel in short-context tasks, their performance in long-context scenarios often falls short due to inadequate long-context alignment. This challenge arises from lacking high-quality, long-context annotated data, as human annotation becomes impractical and unreliable for extended contexts. Additionally, generating synthetic long-context data using LLMs is computationally expensive and lacks scalability. Existing alignment techniques like Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and Direct Preference Optimization (DPO) have significantly improved short-context performance. Still, their effectiveness in long-context alignment remains constrained. Simply extending short-context datasets has proven insufficient, and current alignment strategies prioritize short-context proficiency at the expense of long-context capabilities. As a result, even advanced models like GPT-4, which excel in short-context tasks, may underperform in long-context settings compared to smaller models optimized for extended contexts.
Researchers have explored various strategies for extending LLM context lengths to address these challenges, including scaling rotary position embeddings, continual pretraining on long-document corpora, and hierarchical attention mechanisms. While these methods enhance long-context performance, they often require extensive computational resources or human-annotated data, limiting their scalability. Recent studies have highlighted the potential of self-evolving LLMs, where models iteratively improve by training on self-generated responses ranked through techniques like LLM-as-a-Judge. By leveraging self-augmentation and instruction backtranslation, LLMs can refine their long-context capabilities without external annotations. This approach presents a promising direction for developing long-context LLMs that maintain short- and long-context proficiency while minimizing reliance on costly human annotations.
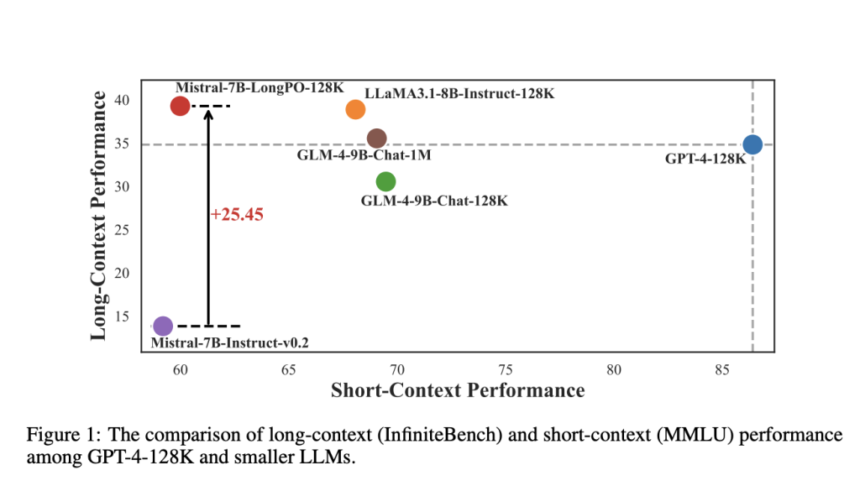
Researchers from institutions including the National University of Singapore, DAMO Academy, and Alibaba Group propose LongPO, which enables short-context LLMs to self-adapt for long-context tasks. LongPO leverages self-generated short-to-long preference data, where paired responses to identical instructions—one with a full long-context input and another with a compressed short-context version—help retain learned capabilities. It employs a short-to-long KL constraint to maintain short-context performance. Applied to Mistral-7B-Instruct, LongPO achieves significant performance gains, surpassing naive SFT and DPO while matching superior LLMs like GPT-4-128K without requiring extensive long-context training or human annotation.
LongPO (Short-to-Long Preference Optimization) enables a short-context LLM to evolve into a long-context model while retaining its original capabilities. It leverages short-to-long preference data to guide learning without external annotation. The approach introduces a KL divergence-based constraint to balance short- and long-context performance. LongPO follows an iterative self-evolving process, where a short-context model generates training data for progressively longer contexts. The model is trained using a multi-turn objective, aggregating responses across different chunks of long documents. LongPO incorporates a negative log-likelihood loss over entire chosen sequences to ensure stability, refining long-context alignment while preserving short-context quality.
The study evaluates LongPO’s effectiveness through two comparisons: (1) against SFT and DPO trained on the same model and dataset and (2) against state-of-the-art long-context LLMs. Using Mistral-7B, LongPO consistently outperforms SFT and DPO by 10–20+ points across tasks while preserving short-context performance. The improvement is due to its explicit short-to-long preference integration. LongPO also surpasses several long-context models of similar scale and even rivals GPT-4-128K in certain benchmarks. Ablation studies confirm that LongPO’s short-to-long constraint and NLL loss significantly enhance performance, highlighting its efficiency in transferring knowledge from short to long contexts without extensive manual annotations.
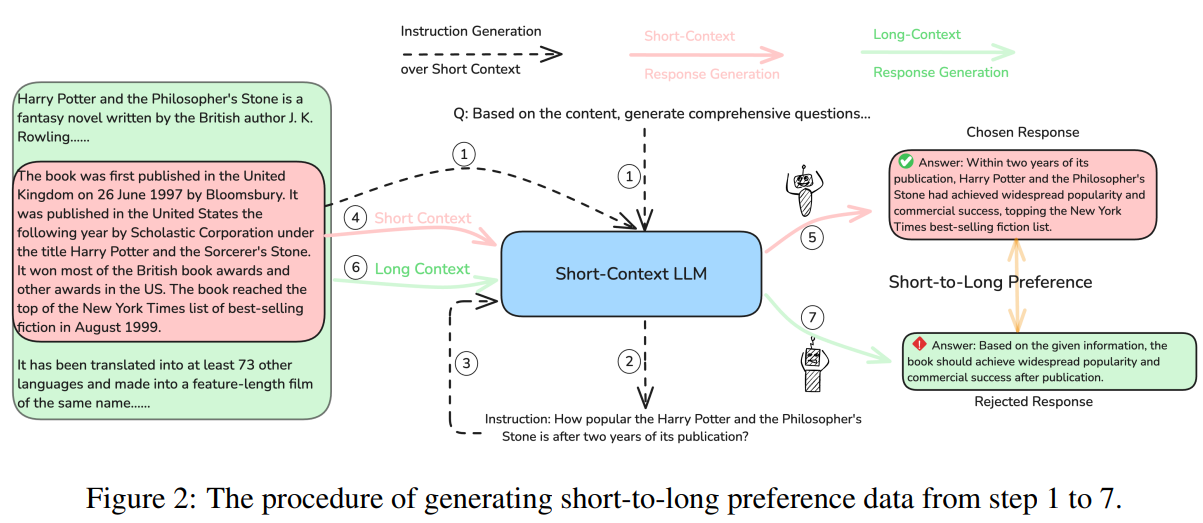
In conclusion, LongPO is designed to align LLMs for long-context tasks by leveraging their inherent short-context capabilities without requiring external annotations. It uses self-generated short-to-long preference data, where responses to the same instruction with both long and short contexts guide alignment. A KL divergence constraint ensures that short-context performance is preserved during training. Applied to Mistral-7B-Instruct-v0.2, LongPO retains short-context proficiency while significantly improving long-context performance, surpassing SFT DPO, and even competing with models like GPT-4-128K. This approach highlights the potential of internal model knowledge for efficient long-context adaptation without extensive manual labeling.
Check out the Paper and GitHub Repo. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post LongPO: Enhancing Long-Context Alignment in LLMs Through Self-Optimized Short-to-Long Preference Learning appeared first on MarkTechPost.