
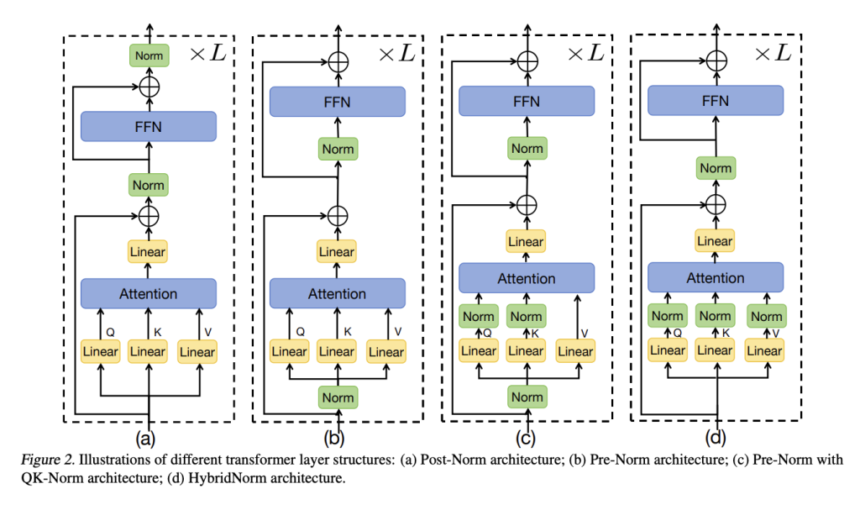


Transformers have revolutionized natural language processing as the foundation of large language models (LLMs), excelling in modeling long-range dependencies through self-attention mechanisms. However, as these models grow deeper and more complex, training stability presents a significant challenge that directly impacts performance. Researchers face a troublesome trade-off between two primary normalization strategies: Pre-Layer Normalization (Pre-Norm) and Post-Layer Normalization (Post-Norm). Pre-Norm offers improved training stability but compromises in final model performance, while Post-Norm delivers superior generalization and performance at the cost of training difficulty. This stability-performance dilemma has hindered the advancement of transformer architectures.
Existing methods tried to enhance transformer architectures in computational efficiency and model expressiveness. Architecture modifications like Multi-head Latent Attention (MLA) and Mixture of Experts (MoE) have improved performance across various tasks but require careful integration with normalization layers. In normalization types, methods like RMSNorm have shown effectiveness in specific contexts by addressing internal covariate shift using root mean square statistics. Regarding attention normalization, QK-Norm enhances stability by normalizing query and key components, while QKV-Norm extends this approach to include value components. Solutions like DeepNorm address training instability by scaling residual connections, while Mix-LN applies Post-Norm to earlier layers and Pre-Norm to deeper layers.
Researchers from Peking University, SeedFoundation-Model ByteDance, and Capital University of Economics and Business have proposed HybridNorm, a normalization strategy to combine the strengths of both Pre-Norm and Post-Norm approaches in transformer architectures effectively. It implements a dual normalization technique within each transformer block: applying QKV normalization within the attention mechanism while utilizing Post-Norm in the feed-forward network (FFN). This strategic combination addresses the longstanding stability-performance trade-off that has challenged transformer model development. The approach proves particularly effective for LLMs, where training stability and performance optimization are crucial.

The HybridNorm is evaluated across two model series: dense models (550M and 1B parameters) and MoE models. The 1B dense model contains approximately 1.27 billion parameters with an architecture similar to Llama 3.2. For the MoE variant, researchers implemented the OLMoE framework, which activates only 1.3B parameters from a total of 6.9B. The 550M dense model features a model dimension of 1536, an FFN dimension of 4096, and 16 attention heads. The larger 1.2B model expands these dimensions to 2048 and 9192, respectively, with 32 attention heads. The MoE-1B-7B model implements a specialized configuration with 16 attention heads and 2048 model dimensions and selectively activates 8 experts from a pool of 64, enabling more efficient computational resource allocation.
The experimental results reveal HybridNorm’s superior performance across dense and MoE models. In dense model evaluations, both HybridNorm and HybridNorm* configurations show consistently lower training loss and validation perplexity than traditional Pre-Norm approaches. Downstream benchmark evaluations show HybridNorm* outperforming the Pre-Norm across diverse tasks, achieving the highest average scores with improvements in BasicArithmetic (+3.11), HellaSwag (+1.71), and COPA (+3.78). In the MoE model, HybridNorm* maintains its advantage with consistently lower training loss and validation perplexity throughout training. Downstream task evaluations for MoE models show improvements in reasoning-intensive tasks like ARC-C (+2.35), ARC-E (+2.40), and OpenbookQA (+0.81).
In conclusion, researchers introduced HybridNorm, a significant advancement in transformer architecture design to resolve the traditional trade-off between training stability and model performance. It strategically combines Pre-Norm and Post-Norm techniques within each transformer block, applying QKV normalization in the attention mechanism and Post-Norm in the feed-forward network. This hybrid strategy creates a balanced normalization framework to stabilize gradient flow while maintaining strong regularization effects. Moreover, the consistent performance gains across various model scales highlight HybridNorm’s versatility and scalability in transformer design. As transformer models, HybridNorm offers a practical solution for developing more robust and performant large-scale neural networks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.


 It’s operated using an easy-to-use CLI
It’s operated using an easy-to-use CLI  and native client SDKs in Python and TypeScript
and native client SDKs in Python and TypeScript  .
.The post HybridNorm: A Hybrid Normalization Strategy Combining Pre-Norm and Post-Norm Strengths in Transformer Architectures appeared first on MarkTechPost.

