


Pre-trained LLMs require instruction tuning to align with human preferences. Still, the vast data collection and rapid model iteration often lead to oversaturation, making efficient data selection a crucial yet underexplored area. Existing quality-driven selection methods, such as LIMA and AlpaGasus, tend to overlook the importance of data diversity and complexity, essential for enhancing model performance. While scaling LLMs has proven beneficial, optimizing instruction fine-tuning (IFT) relies on training data’s quality, diversity, and complexity. However, measuring these factors remains challenging, with recent research calling for quantifiable metrics to assess dataset diversity rather than relying on subjective claims. Sparse autoencoders (SAEs) have recently emerged as effective tools for interpreting LLMs by ensuring mono-semantic representations, making them valuable for analyzing data selection mechanisms.
Sparse autoencoders have significantly improved LLM interpretability by enforcing sparsity in representations, thereby enhancing feature independence. Early works in sparse coding and dictionary learning laid the foundation for structured data representations, later applied to transformers to decode contextual embeddings. Recent research has highlighted the challenges of polysemantic neurons encoding multiple concepts, prompting efforts to develop monosemantic neurons for better interpretability. In parallel, data selection methods, such as ChatGPT-based scoring and gradient-based clustering, have been explored to refine instruction tuning. Despite advancements, accurately quantifying data quality, diversity, and complexity remains complex, necessitating further research into effective metrics and selection strategies to optimize instruction tuning in LLMs.
Researchers at Meta GenAI introduce a diversity-aware data selection strategy using SAEs to improve instruction tuning. SAEs help quantify data diversity and enhance model interpretability, explaining methods like selecting the longest response. They develop two selection algorithms: SAE-GreedSelect for limited data and SAE-SimScale for larger datasets. Experiments on Alpaca and WizardLM_evol_instruct_70k datasets demonstrate superior performance over prior techniques. Their approach refines data selection, reduces training costs, and offers deeper insights into model behavior, making instruction tuning more efficient and interpretable.
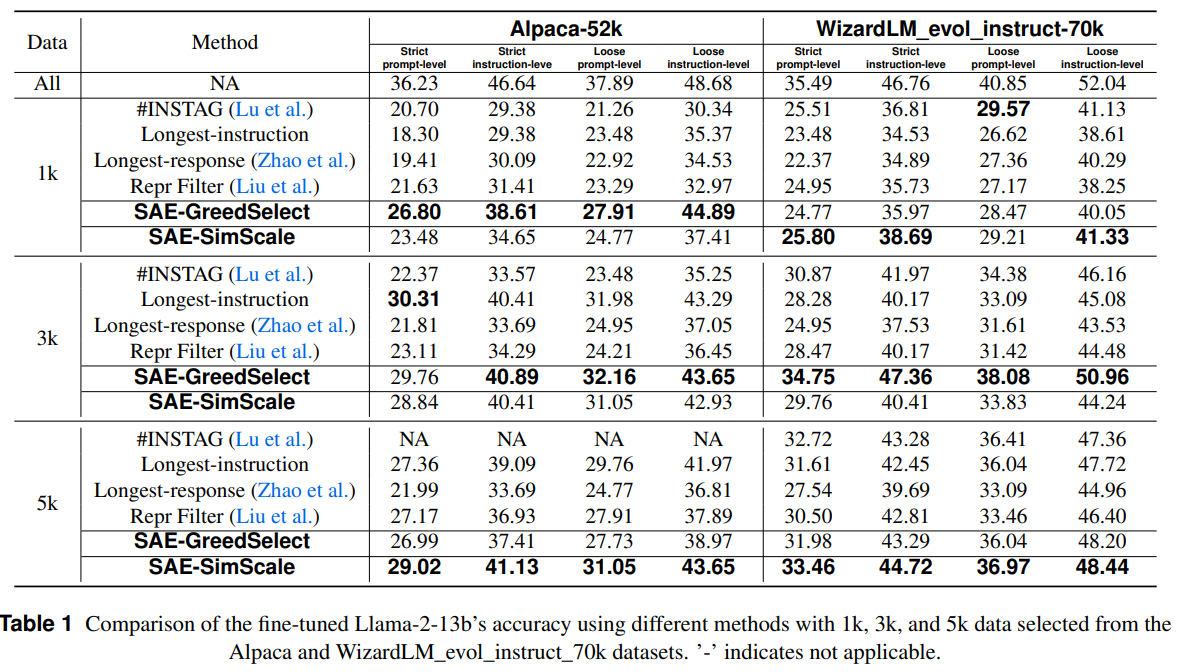
The study introduces two diversity-driven data selection methods using SAEs. SAE-GreedSelect optimizes feature utilization for selecting limited data, while SAE-SimScale scales data selection using similarity-based sampling. Experiments on Llama-2-13b, Gemma-2-9b, and Llama-2-7b-base validate the approach using Alpaca-52k and WizardLM_evol_instruct_70k datasets. Comparisons with baselines like Longest-response, #InsTag, and Repr Filter demonstrate superior performance. Models are trained using standardized settings and evaluated with IFEval, LLM- and Human-as-a-Judge methods, and benchmarks like MMLU and TruthfulQA. Results highlight improved instruction tuning efficiency and interpretability while maintaining simplicity in parameter tuning.
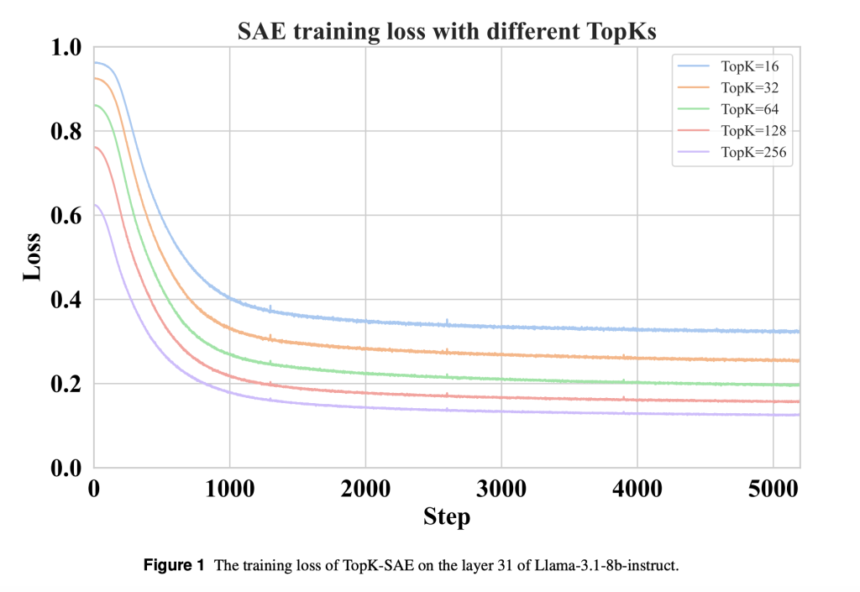
Selecting the 1,000 longest responses is an effective baseline for supervised fine-tuning (SFT), likely because longer responses contain more learnable information. A strong correlation (r = 0.92) between text length and feature richness in an SAE supports this hypothesis. The proposed data selection methods, SAE-GreedSelect and SAE-SimScale, outperform existing baselines, particularly at larger data scales. SAE-SimScale achieves notable improvements across multiple datasets and evaluation metrics, highlighting its robustness. Further experiments confirm its effectiveness across model sizes and architectures, reinforcing its potential for optimizing scalable data selection strategies.
In conclusion, the study introduces an approach to measuring data diversity using learned monosemanticity in sparse autoencoders. A new data selection algorithm for instruction tuning was developed, improving model performance across various datasets. The method consistently outperforms existing selection techniques and demonstrates that longer instruction-response pairs enhance model capabilities. The approach also improves efficiency by reducing data requirements and training costs. Additionally, it offers insights into model behavior and can be extended to preference data selection or improving model safety. This strategy ensures better alignment with human preferences while maintaining diversity and complexity in training data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Enhancing Instruction Tuning in LLMs: A Diversity-Aware Data Selection Strategy Using Sparse Autoencoders appeared first on MarkTechPost.

