


Tokenization plays a fundamental role in the performance and scalability of Large Language Models (LLMs). Despite being a critical component, its influence on model training and efficiency remains underexplored. While larger vocabularies can compress sequences and reduce computational costs, existing approaches tie input and output vocabularies together, creating trade-offs where scaling benefits larger models but harms smaller ones. This paper introduces a framework called Over-Tokenized Transformers that reimagines vocabulary design by decoupling input and output tokenization, unlocking new pathways for model efficiency and performance.
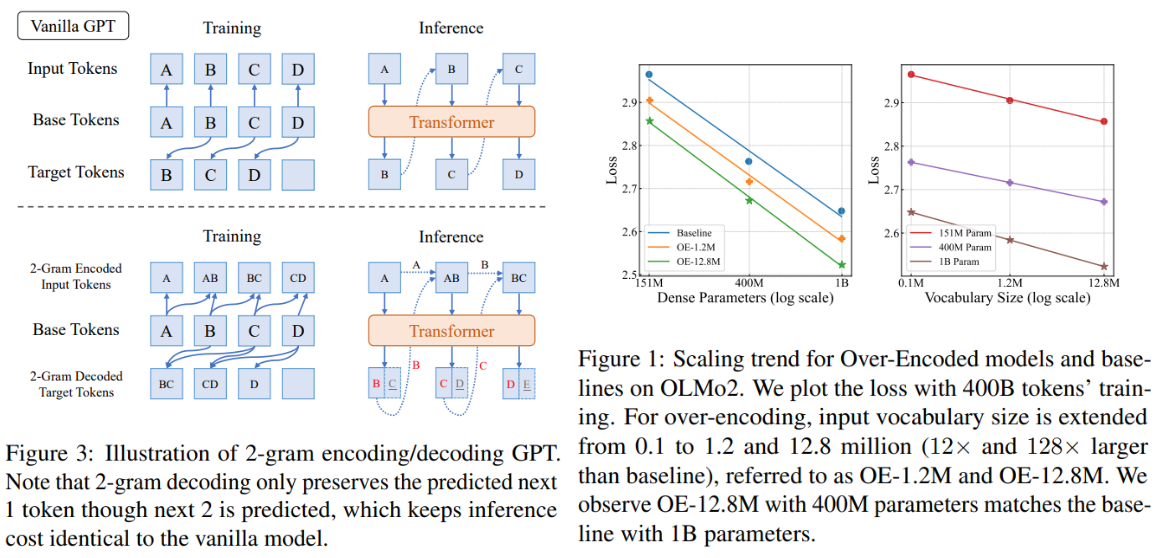
Traditional tokenization methods use identical vocabularies for input processing and output prediction. While larger vocabularies allow models to process longer n-gram tokens (e.g., multi-character sequences), they force smaller models to handle overly granular output predictions, increasing underfitting risks. For instance, a 3-gram tokenizer reduces sequence length by 66% but requires predicting three characters jointly—a task manageable for large models but overwhelming for smaller ones. Previous work like multi-token prediction (MTP) attempted to address this by predicting future tokens in parallel, but these methods still entangled input/output granularity and struggled with smaller architectures.
The research team identified a critical insight through synthetic experiments with context-free grammars: input and output vocabularies influence models differently. Larger input vocabularies consistently improved all model sizes by enriching context representations through multi-gram embeddings. Conversely, larger output vocabularies introduced fine-grained prediction tasks that only benefited sufficiently large models. This dichotomy motivated their Over-Tokenized framework, which separates input encoding (Over-Encoding) and output decoding (Over-Decoding) vocabularies.
Over-Encoding (OE) scales input vocabularies exponentially using hierarchical n-gram embeddings. Instead of a single token ID, each input token is represented as the sum of 1-, 2-, and 3-gram embeddings. For example, the word “cat” might decompose into embeddings for “c,” “ca,” and “cat,” allowing the model to capture multi-scale contextual cues. To avoid impractical memory costs from large n-gram tables (e.g., 100k³ entries), the team used parameter-efficient techniques:
- Modulo-based token hashing: Maps n-gram tokens to a fixed-size embedding table using modular arithmetic, enabling dynamic vocabulary expansion without storing all possible combinations.
- Embedding decomposition: Splits high-dimensional embeddings into smaller, stacked matrices, reducing memory access costs while preserving representational capacity.
Over-Decoding (OD) approximates larger output vocabularies by predicting multiple future tokens sequentially, a refinement of earlier MTP methods. For instance, instead of predicting one token at a time, OD trains the model to predict the next two tokens conditioned on the first prediction. Crucially, OD is selectively applied—only larger models benefit from this granular supervision, while smaller ones retain single-token decoding to avoid underfitting.
The researchers performed experiments on OLMo and OLMoE architectures and demonstrated three key findings:
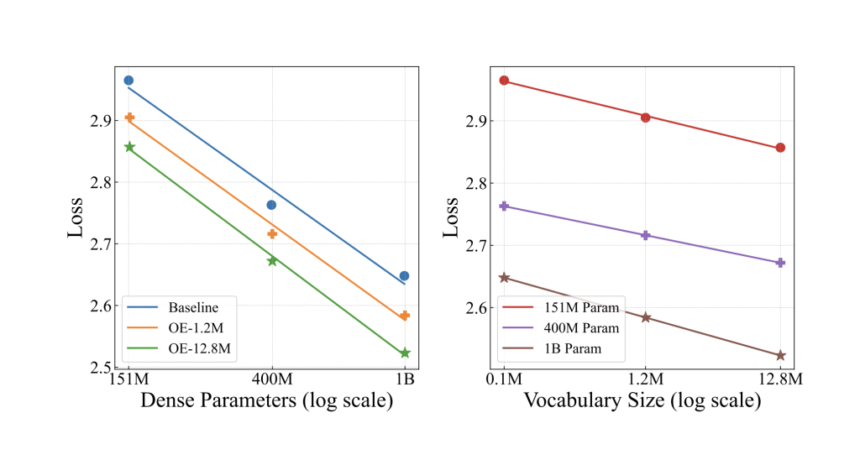
- Log-Linear Scaling: Training loss decreased linearly as input vocabulary size grew exponentially (Figure 1). A 400M parameter model with a 12.8M-entry input vocabulary matched the performance of a 1B-parameter baseline, achieving 2.5× effective scaling at equal computational cost.
- Convergence Acceleration: Over-Encoding reduced training steps needed for convergence by 3–5× across tasks like MMLU and PIQA, suggesting richer input representations accelerate learning.
- Sparse Parameter Efficiency: Despite using 128× larger input vocabularies, memory and computation overheads increased by <5% due to sparse embedding access and optimized sharding strategies.
On evaluations, the framework demonstrated consistent performance improvements across various model types. For dense models, a 151M Over-Encoded (OE) model achieved a 14% reduction in perplexity compared to its baseline. Similarly, in sparse Mixture-of-Experts (MoE) models, the OLMoE-1.3B with OE reduced validation loss by 0.12 points, although the gains were less pronounced as the benefits of sparse experts diluted the impact of embedding enhancements. Beyond synthetic experiments, real-world evaluations on large-scale datasets further validated these findings. Over-Encoded models consistently improved performance across multiple benchmarks, including MMLU-Var, Hellaswag, ARC-Challenge, ARC-Easy, and PIQA. Notably, the framework accelerated convergence, achieving a 5.7× speedup in training loss reduction. Additionally, downstream evaluations showed significant acceleration, with OE delivering speedups of 3.2× on MMLU-Var, 3.0× on Hellaswag, 2.6× on ARC-Challenge, 3.1× on ARC-Easy, and 3.9× on PIQA, highlighting its efficiency and effectiveness across diverse tasks.
In conclusion, this work redefines tokenization as a scalable dimension in language model design. By decoupling input and output vocabularies, Over-Tokenized Transformers break traditional trade-offs, enabling smaller models to benefit from compressed input sequences without grappling with overly complex prediction tasks. The log-linear relationship between input vocabulary size and performance suggests embedding parameters represent a new axis for scaling laws, complementing existing work on model depth and width. Practically, the framework offers a low-cost upgrade path for existing architectures—integrating Over-Encoding requires minimal code changes but yields immediate efficiency gains. Future research could explore hybrid tokenization strategies or dynamic vocabulary adaptation, further solidifying tokenization’s role in the next generation of efficient, high-performing LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.
 Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
The post Decoupling Tokenization: How Over-Tokenized Transformers Redefine Vocabulary Scaling in Language Models appeared first on MarkTechPost.


