


This paper was just accepted at CVPR 2025. In short, CASS is as an elegant solution to Object-Level Context in open-world segmentation. They outperform several training-free approaches and even surpasses some methods that rely on extra training. The gains are especially notable in challenging setups where objects have intricate sub-parts or classes have high visual similarity. Results show that CASS consistently predicts correct labels down to the pixel level, underscoring its refined object-level awareness.

Want to know how they did it? Read below …code link is available at the end.
Distilling Spectral Graphs for Object-Level Context: A Novel Leap in Training-Free Open-Vocabulary Semantic Segmentation
Open-vocabulary semantic segmentation (OVSS) is shaking up the landscape of computer vision by allowing models to segment objects based on any user-defined prompt—without being tethered to a fixed set of categories. Imagine telling an AI to pick out every “Space Needle” in a cityscape or to detect and segment an obscure object you just coined. Traditional segmentation pipelines, typically restricted to a finite set of training classes, can’t handle such requests without extra finetuning or retraining. Enter CASS (Context-Aware Semantic Segmentation), a bold new approach that harnesses powerful large-scale, pre-trained models to achieve high-fidelity, object-aware segmentation entirely without additional training.
The Rise of Training-Free OVSS
Conventional supervised approaches for semantic segmentation require extensive labeled datasets. While they excel at known classes, they often struggle or overfit when faced with new classes not seen during training. In contrast, training-free OVSS methods—often powered by large-scale vision-language models like CLIP—are able to segment based on novel textual prompts in a zero-shot manner. This aligns naturally with the flexibility demanded by real-world applications, where it’s impractical or extremely costly to anticipate every new object that might appear. And because they are training-free, these methods require no further annotation or data collection every time the use case changes…making this a very scalable for production level solutions.
Despite these strengths, existing training-free methods face a fundamental hurdle: object-level coherence. They often nail the broad alignment between image patches and text prompts (e.g., “car” or “dog”) but fail to unify the entire object—like grouping the wheels, roof, and windows of a truck under a single coherent mask. Without an explicit way to encode object-level interactions, crucial details end up fragmented, limiting overall segmentation quality.
CASS: Injecting Object-Level Context for Coherent Segmentation
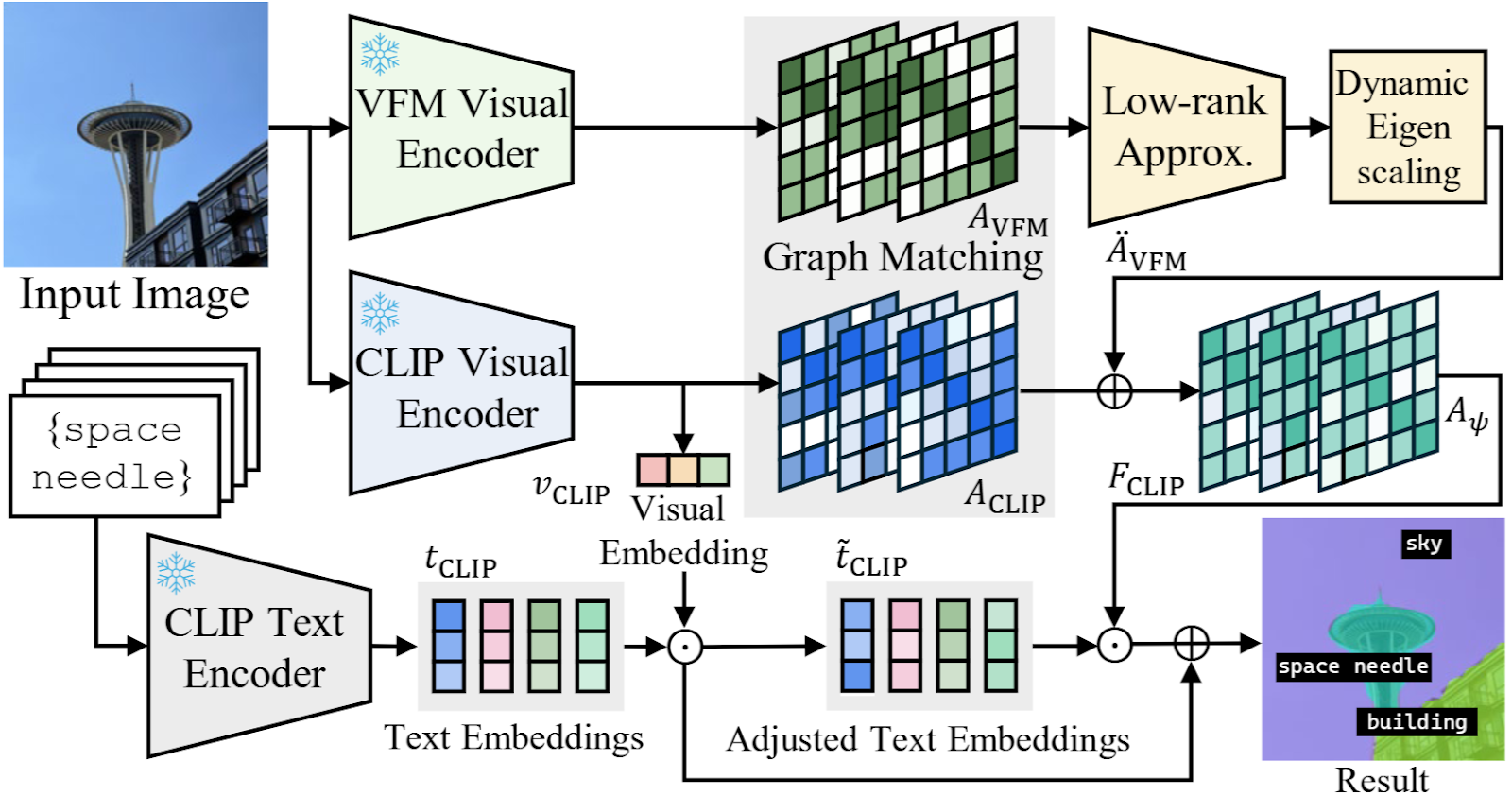
To address this shortfall, the authors from Yonsei University and UC Merced introduce CASS, a system that distills rich object-level knowledge from Vision Foundation Models (VFMs) and aligns it with CLIP’s text embeddings.
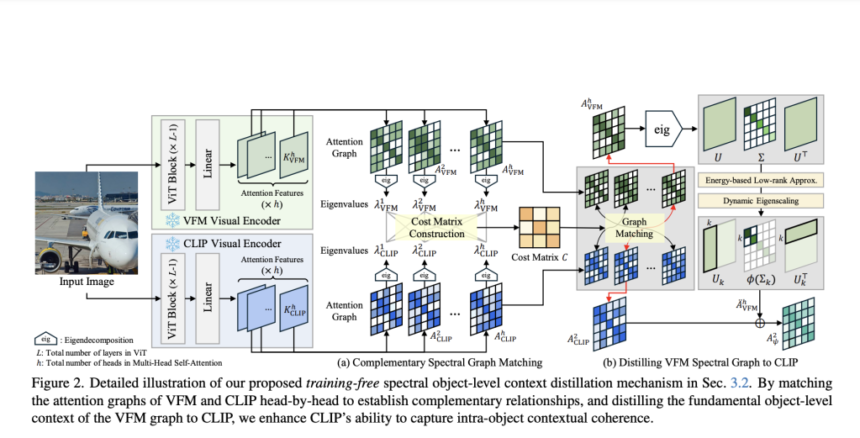
Two core insights power this approach:
- Spectral Object-Level Context Distillation
While CLIP excels at matching textual prompts with global image features, it doesn’t capture fine-grained, object-centric context. On the other hand, VFMs like DINO do learn intricate patch-level relationships but lack direct text alignment.
CASS bridges these strengths by treating both CLIP and the VFM’s attention mechanisms as graphs and matching their attention heads via spectral decomposition. In other words, each attention head is examined through its eigenvalues, which reflect how patches correlate with one another. By pairing complementary heads—those that focus on distinct structure—CASS effectively transfers object-level context from the VFM into CLIP.
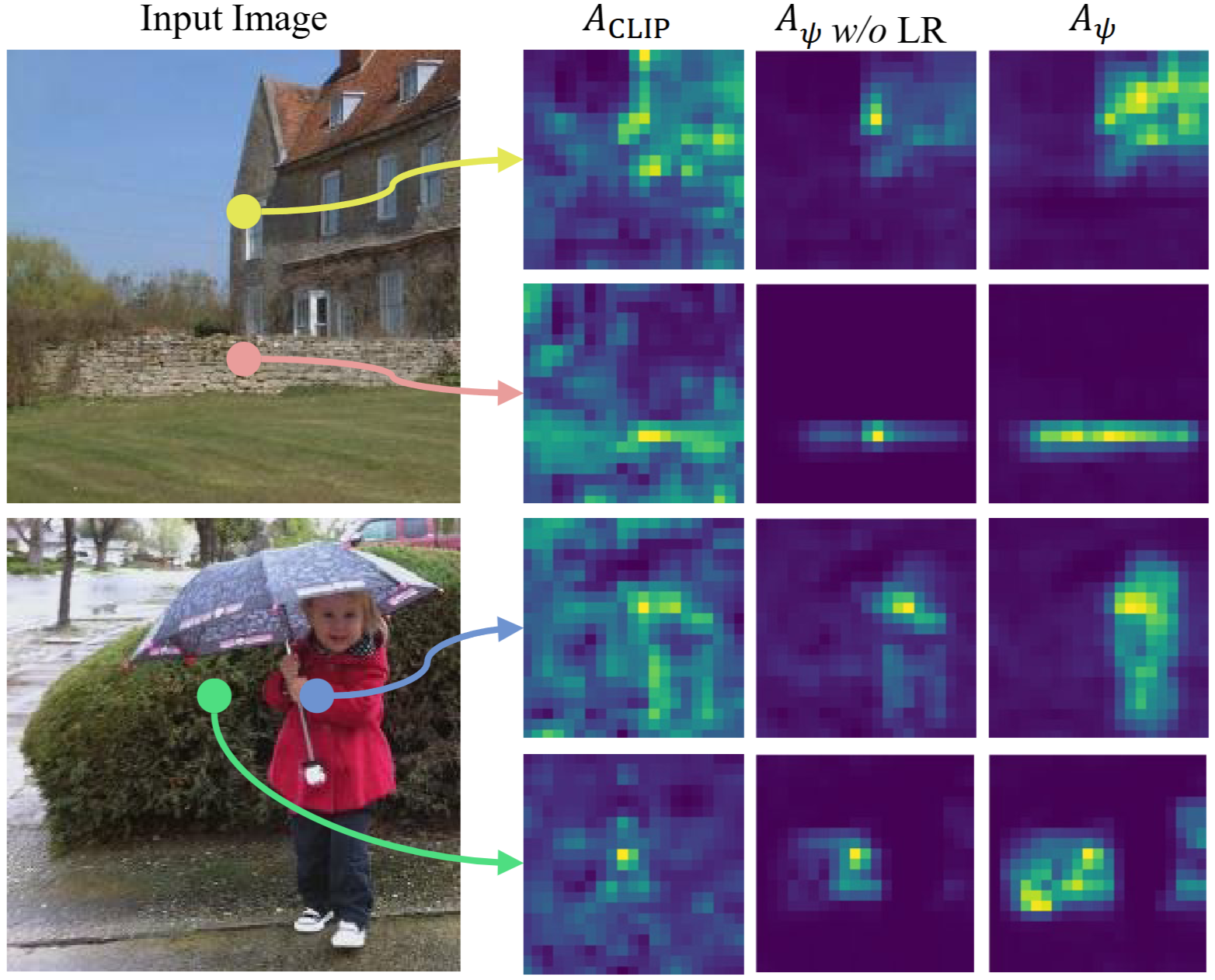
To avoid noise, the authors apply low-rank approximation on the VFM’s attention graph, followed by dynamic eigenvalue scaling. The result is a distilled representation that highlights core object boundaries while filtering out irrelevant details—enabling CLIP to finally “see” all parts of a truck (or any object) as one entity.
- Object Presence Prior for Semantic Refinement
OVSS means the user can request any prompt, but this can lead to confusion among semantically similar categories. For example, prompts like “bus” vs. “truck” vs. “RV” might cause partial mix-ups if all are somewhat likely.
CASS tackles this by leveraging CLIP’s zero-shot classification capability. It computes an object presence prior, estimating how likely each class is to appear in the image overall. Then, it uses this prior in two ways:
Refining Text Embeddings: It clusters semantically similar prompts and identifies which labels are most likely in the image, steering the selected text embeddings closer to the actual objects.
Object-Centric Patch Similarity: Finally, CASS fuses the patch-text similarity scores with these presence probabilities to get sharper and more accurate predictions.
Taken together, these strategies offer a robust solution for true open-vocabulary segmentation. No matter how new or unusual the prompt, CASS efficiently captures both the global semantics and the subtle details that group an object’s parts.
Results are impressive, see below, Right column is CASS, you can clearly see object level segmentation..much better then CLIP
Under the Hood: Matching Attention Heads via Spectral Analysis
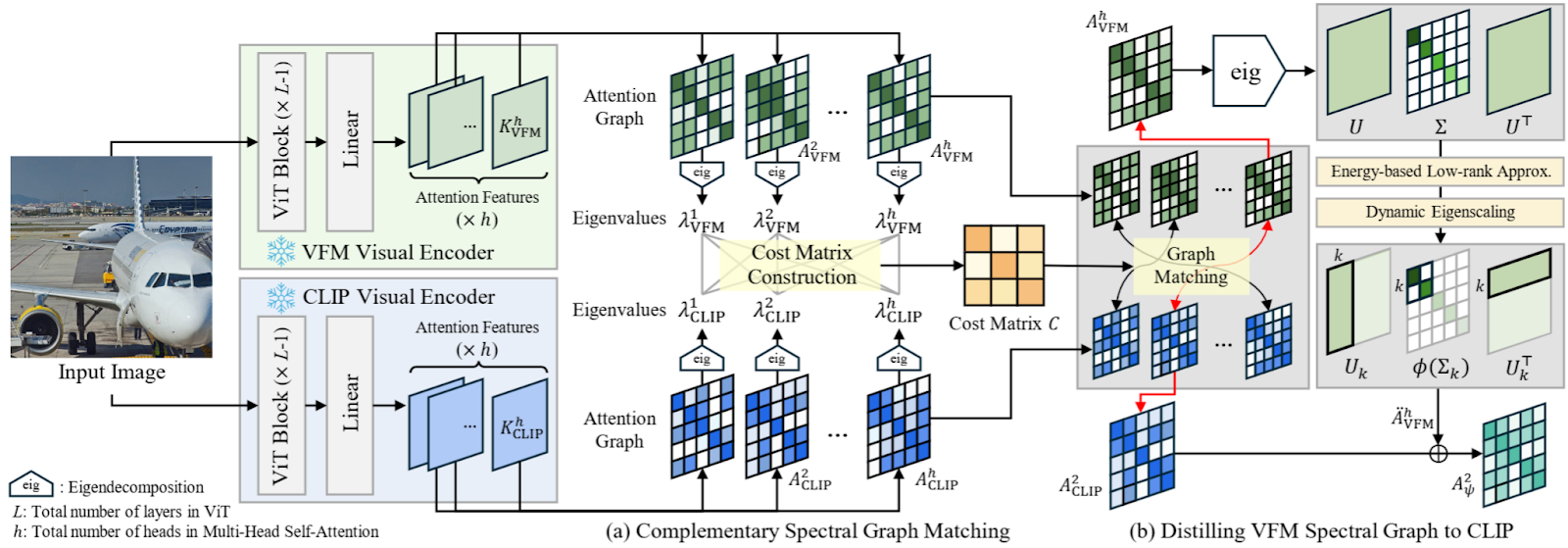
One of CASS’s most innovative points is how it matches CLIP and VFM attention heads. Each attention head behaves differently; some might home in on color/texture cues while others lock onto shape or position. So, the authors perform an eigenvalue decomposition on each attention map to reveal its unique “signature.”
- A cost matrix is formed by comparing these signatures using the Wasserstein distance, a technique that measures the distance between distributions in a way that captures overall shape.
- The matrix is fed to the Hungarian matching algorithm, which pairs heads that have contrasting structural distributions.
- The VFM’s matched attention heads are low-rank approximated and scaled to emphasize object boundaries.
- Finally, these refined heads are distilled into CLIP’s attention, augmenting its capacity to treat each object as a unified whole.
Qualitatively, you can think of this process as selectively injecting object-level coherence: after the fusion, CLIP now “knows” a wheel plus a chassis plus a window equals one truck.
Why Training-Free Matters
- Generalization: Because CASS doesn’t need additional training or finetuning, it generalizes far better to out-of-domain images and unanticipated classes.
- Immediate Deployment: Industrial or robotic systems benefit from the instant adaptability—no expensive dataset curation is needed for each new scenario.
- Efficiency: With fewer moving parts and no annotation overhead, the pipeline is remarkably efficient for real-world use.
At the end of the day..for any production level solution training free is key to handle long tail use cases.
Empirical Results
CASS undergoes thorough testing on eight benchmark datasets, including PASCAL VOC, COCO, and ADE20K, which collectively cover over 150 object categories. Two standout metrics emerge:
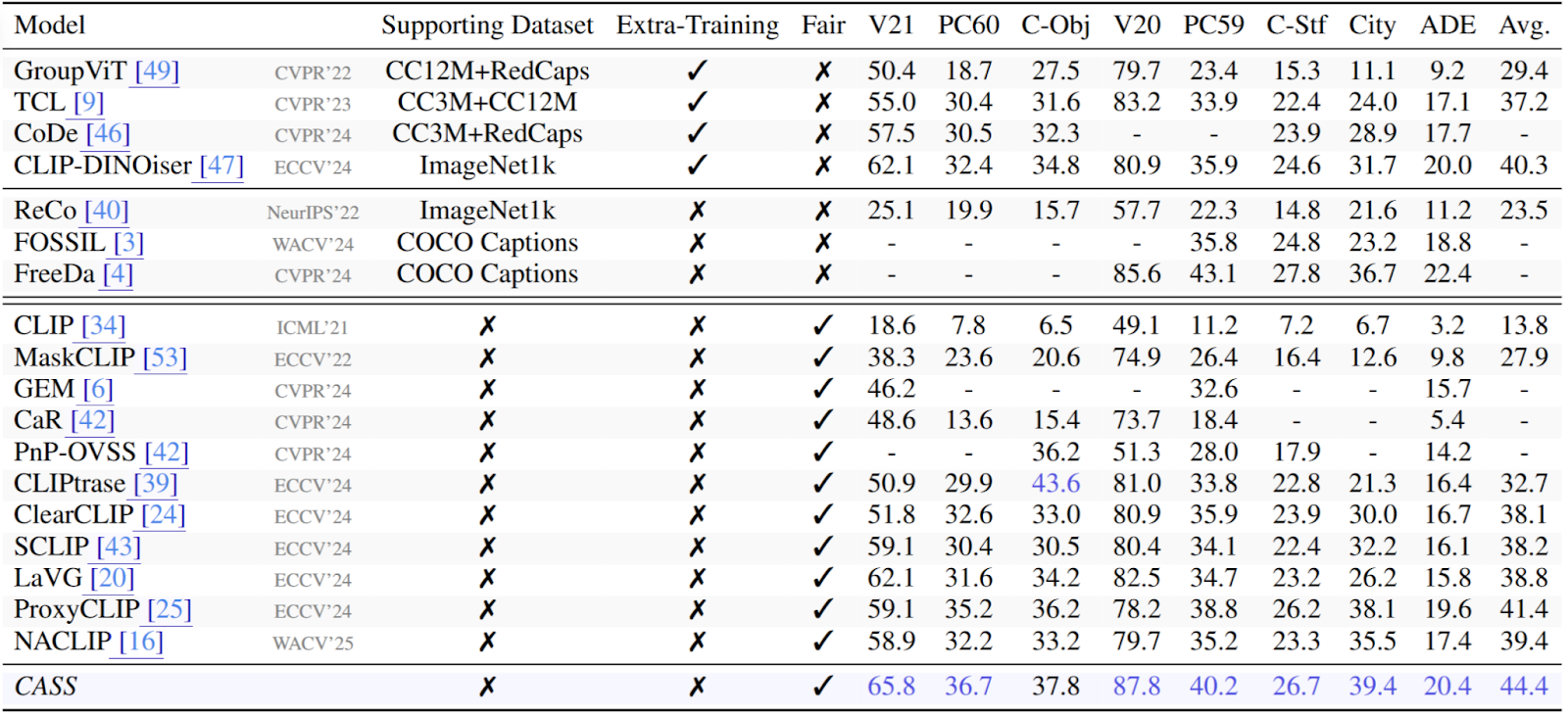
- Mean Intersection over Union (mIoU): CASS outperforms several training-free approaches and even surpasses some methods that rely on extra training. The gains are especially notable in challenging setups where objects have intricate sub-parts or classes have high visual similarity.
- Pixel Accuracy (pAcc): Results show that CASS consistently predicts correct labels down to the pixel level, underscoring its refined object-level awareness.
Unlocking True Open-Vocabulary Segmentation
The release of CASS marks a leap forward for training-free OVSS. By distilling spectral information into CLIP and by fine-tuning text prompts with an object presence prior, it achieves a highly coherent segmentation that can unify an object’s scattered parts—something many previous methods struggled to do. Whether deployed in robotics, autonomous vehicles, or beyond, this ability to recognize and segment any object the user names is immensely powerful and frankly required.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post CASS: Injecting Object-Level Context for Advanced Open-vocabulary semantic segmentation appeared first on MarkTechPost.

