

AI agents are increasingly vital in helping engineers efficiently handle complex coding tasks. However, one significant challenge has been accurately assessing and ensuring these agents can handle real-world coding scenarios beyond simplified benchmark tests.
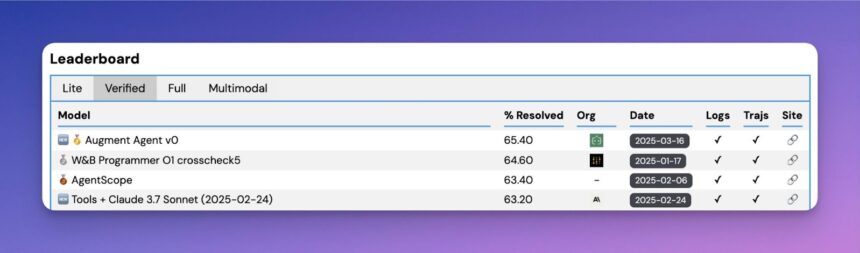
Augment Code has announced the launch of their Augment SWE-bench Verified Agent, a development in agentic AI tailored specifically for software engineering. This release places them at the top of open-source agent performance on the SWE-bench leaderboard. By combining the strengths of Anthropic’s Claude Sonnet 3.7 and OpenAI’s O1 model, Augment Code’s approach has delivered impressive results, showcasing a compelling blend of innovation and pragmatic system architecture.
The SWE-bench benchmark is a rigorous test that measures an AI agent’s effectiveness in handling practical software engineering tasks drawn directly from GitHub issues in prominent open-source repositories. Unlike traditional coding benchmarks, which generally focus on isolated, algorithmic-style problems, SWE-bench offers a more realistic testbed that requires agents to navigate existing codebases, identify relevant tests autonomously, create scripts, and iterate against comprehensive regression test suites.
Augment Code’s initial submission has achieved a 65.4% success rate, a notable achievement in this demanding environment. The company focused its first effort on leveraging existing state-of-the-art models, specifically Anthropic’s Claude Sonnet 3.7 as the primary driver for task execution and OpenAI’s O1 model for ensembling. This approach strategically bypassed training proprietary models at this initial phase, establishing a robust baseline.

One interesting aspect of Augment’s methodology was their exploration into different agent behaviors and strategies. For example, they found that certain expected beneficial techniques like Claude Sonnet’s ‘thinking mode’ and separate regression-fixing agents did not yield meaningful performance improvements. This highlights the nuanced and sometimes counterintuitive dynamics in agent performance optimization. Also, basic ensembling techniques such as majority voting were explored but ultimately abandoned due to cost and efficiency considerations. However, simple ensembling with OpenAI’s O1 did provide incremental improvements in accuracy, underscoring the value of ensembling even in constrained scenarios.
While Augment Code’s initial SWE-bench submission’s success is commendable, the company is transparent about the benchmark’s limitations. Notably, SWE-bench problems are heavily skewed toward bug fixing rather than feature creation, the provided descriptions are more structured and LLM-friendly compared to typical real-world developer prompts, and the benchmark solely utilizes Python. Real-world complexities, such as navigating massive production codebases and dealing with less descriptive programming languages, pose challenges that SWE-bench does not capture.
Augment Code has openly acknowledged these limitations, emphasizing its continued commitment to optimizing agent performance beyond benchmark metrics. They stress that while improvements to prompts and ensembling can boost quantitative results, qualitative customer feedback and real-world usability remain its priorities. The ultimate goal for Augment Code is developing cost-effective, fast agents capable of providing unparalleled coding assistance in practical professional environments.
As part of its future roadmap, Augment is actively exploring the fine-tuning of proprietary models using RL techniques and proprietary data. Such advancements promise to enhance model accuracy and significantly reduce latency and operational costs, facilitating more accessible and scalable AI-driven coding assistance.
Some of the key takeaways from the Augment SWE-bench Verified Agent include:
- Augment Code released Augment SWE-bench Verified Agent, achieving the top spot among open-source agents.
- The agent combines Anthropic’s Claude Sonnet 3.7 as its core driver and OpenAI’s O1 model for ensembling.
- Achieved a 65.4% success rate on SWE-bench, highlighting robust baseline capabilities.
- Found counterintuitive results, where anticipated beneficial features like ‘thinking mode’ and separate regression-fixing agents offered no substantial performance gains.
- Identified cost-effectiveness as a critical barrier to implementing extensive ensembling in real-world scenarios.
- Acknowledged benchmark limitations, including its bias towards Python and smaller-scale bug-fixing tasks.
- Future improvements will focus on cost reduction, lower latency, and improved usability through reinforcement learning and fine-tuning proprietary models.
- Highlighted the importance of balancing benchmark-driven improvements with qualitative user-centric enhancements.
Check out the GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
 [Register Now] miniCON Virtual Conference on OPEN SOURCE AI: FREE REGISTRATION + Certificate of Attendance + 3 Hour Short Event (April 12, 9 am- 12 pm PST) + Hands on Workshop [Sponsored]
[Register Now] miniCON Virtual Conference on OPEN SOURCE AI: FREE REGISTRATION + Certificate of Attendance + 3 Hour Short Event (April 12, 9 am- 12 pm PST) + Hands on Workshop [Sponsored]The post Augment Code Released Augment SWE-bench Verified Agent: An Open-Source Agent Combining Claude Sonnet 3.7 and OpenAI O1 to Excel in Complex Software Engineering Tasks appeared first on MarkTechPost.


