


In today’s rapidly evolving digital landscape, the need for accessible, efficient language models is increasingly evident. Traditional large-scale models have advanced natural language understanding and generation considerably, yet they often remain out of reach for many researchers and smaller organizations. High training costs, proprietary restrictions, and a lack of transparency can hinder innovation and limit the development of tailored solutions. With a growing demand for models that balance performance with accessibility, there is a clear call for alternatives that serve both the academic and industrial communities without the typical barriers associated with cutting-edge technology.
Introducing AMD Instella
AMD has recently introduced Instella, a family of fully open-source language models featuring 3 billion parameters. Designed as text-only models, these tools offer a balanced alternative in a crowded field, where not every application requires the complexity of larger systems. By releasing Instella openly, AMD provides the community with the opportunity to study, refine, and adapt the model for a range of applications—from academic research to practical, everyday solutions. This initiative is a welcome addition for those who value transparency and collaboration, making advanced natural language processing technology more accessible without compromising on quality.

Technical Architecture and Its Benefits
At the core of Instella is an autoregressive transformer model structured with 36 decoder layers and 32 attention heads. This design supports the processing of lengthy sequences—up to 4,096 tokens—which enables the model to manage extensive textual contexts and diverse linguistic patterns. With a vocabulary of roughly 50,000 tokens managed by the OLMo tokenizer, Instella is well-suited to interpret and generate text across various domains.

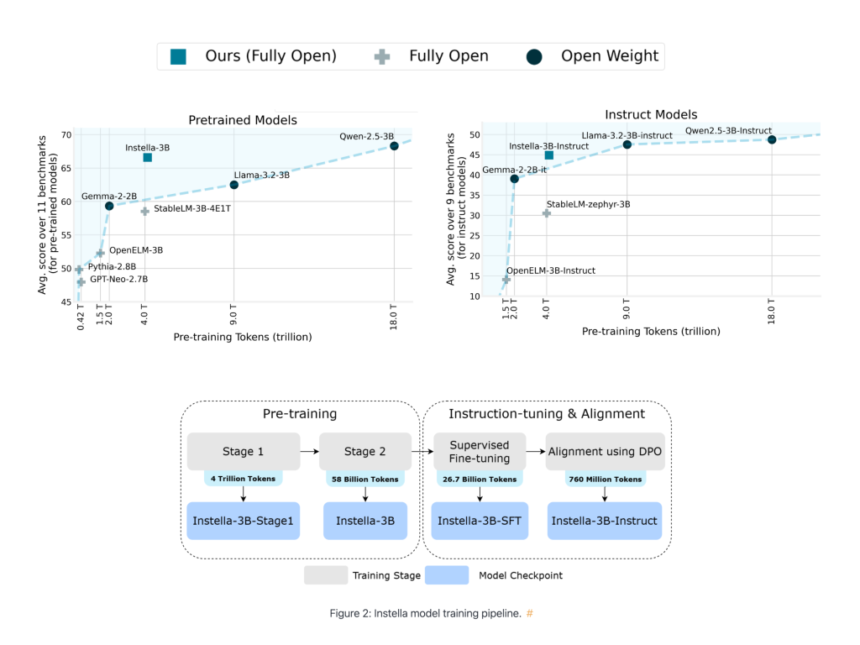
The training process behind Instella is equally noteworthy. The model was trained using AMD Instinct MI300X GPUs, emphasizing the synergy between AMD’s hardware and software innovations. The multi-stage training approach is divided into several parts:
| Model | Stage | Training Data (Tokens) | Description |
|---|---|---|---|
| Instella-3B-Stage1 | Pre-training (Stage 1) | 4.065 Trillion | First stage pre-training to develop proficiency in natural language. |
| Instella-3B | Pre-training (Stage 2) | 57.575 Billion | Second stage pre-training to further enhance problem solving capabilities. |
| Instella-3B-SFT | SFT | 8.902 Billion (x3 epochs) | Supervised Fine-tuning (SFT) to enable instruction-following capabilities. |
| Instella-3B-Instruct | DPO | 760 Million | Alignment to human preferences and strengthen chat capabilities with direct preference optimization (DPO). |
| Total: | 4.15 Trillion |
Additional training optimizations, such as FlashAttention-2 for efficient attention computation, Torch Compile for performance acceleration, and Fully Sharded Data Parallelism (FSDP) for resource management, have been employed. These choices ensure that the model not only performs well during training but also operates efficiently when deployed.
Performance Metrics and Insights
Instella’s performance has been carefully evaluated against several benchmarks. When compared with other open-source models of a similar scale, Instella demonstrates an average improvement of around 8% across multiple standard tests. These evaluations cover tasks ranging from academic problem-solving to reasoning challenges, providing a comprehensive view of its capabilities.
The instruction-tuned versions of Instella, such as those refined through supervised fine-tuning and subsequent alignment processes, exhibit a solid performance in interactive tasks. This makes them suitable for applications that require a nuanced understanding of queries and a balanced, context-aware response. In comparisons with models like Llama-3.2-3B, Gemma-2-2B, and Qwen-2.5-3B, Instella holds its own, proving to be a competitive option for those who need a more lightweight yet robust solution. The transparency of the project—evidenced by the open release of model weights, datasets, and training hyperparameters—further enhances its appeal for those who wish to explore the inner workings of modern language models.
Conclusion
AMD’s release of Instella marks a thoughtful step toward democratizing advanced language modeling technology. The model’s clear design, balanced training approach, and transparent methodology provide a strong foundation for further research and development. With its autoregressive transformer architecture and carefully curated training pipeline, Instella stands out as a practical and accessible alternative for a wide range of applications.
Check out the Technical Details, GitHub Page and Models on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post AMD Releases Instella: A Series of Fully Open-Source State-of-the-Art 3B Parameter Language Model appeared first on MarkTechPost.


