


Most existing LLMs prioritize languages with abundant training resources, such as English, French, and German, while widely spoken but underrepresented languages like Hindi, Bengali, and Urdu receive comparatively less attention. This imbalance limits the accessibility of AI-driven language tools for many global populations, leaving billions without high-quality language processing solutions. Addressing this challenge requires innovative approaches to training and optimizing multilingual LLMs to deliver consistent performance across languages with varying resource availability.
A critical challenge in multilingual NLP is the uneven distribution of linguistic resources. High-resource languages benefit from extensive corpora, while languages spoken in developing regions often lack sufficient training data. This limitation affects the performance of multilingual models, which tend to exhibit better accuracy in well-documented languages while struggling with underrepresented ones. Addressing this gap requires innovative approaches that expand language coverage while maintaining model efficiency.
Several multilingual LLMs have attempted to address this challenge, including Bloom, GLM-4, and Qwen2.5. These models support multiple languages, but their effectiveness depends on the availability of training data. They prioritize languages with extensive textual resources while offering suboptimal performance in languages with scarce data. For example, existing models excel in English, Chinese, and Spanish but face difficulties when processing Swahili, Javanese, or Burmese. Also, many of these models rely on traditional pretraining methods, which fail to accommodate language diversity without increasing computational requirements. Without structured approaches to improving language inclusivity, these models remain inadequate for truly global NLP applications.
Researchers from DAMO Academy at Alibaba Group introduced Babel, a multilingual LLM designed to support over 90% of global speakers by covering the top 25 most spoken languages to bridge this gap. Babel employs a unique layer extension technique to expand its model capacity without compromising performance. The research team introduced two model variants: Babel-9B, optimized for efficiency in inference and fine-tuning, and Babel-83B, which establishes a new benchmark in multilingual NLP. Unlike previous models, Babel includes widely spoken but often overlooked languages such as Bengali, Urdu, Swahili, and Javanese. The researchers focused on optimizing data quality by implementing a rigorous pipeline that curates high-quality training datasets from multiple sources.
Babel’s architecture differs from conventional multilingual LLMs by employing a structured layer extension approach. Rather than relying on continuous pretraining, which requires extensive computational resources, the research team increased the model’s parameter count through controlled expansion. Additional layers were integrated strategically to maximize performance while preserving computational efficiency. For instance, Babel-9B was designed to balance speed and multilingual comprehension, making it suitable for research and localized deployment, whereas Babel-83B extends its capabilities to match commercial models. The model’s training process incorporated extensive data-cleaning techniques, using an LLM-based quality classifier to filter and refine training content. The dataset was sourced from diverse origins, including Wikipedia, news articles, textbooks, and structured multilingual corpora such as MADLAD-400 and CulturaX.

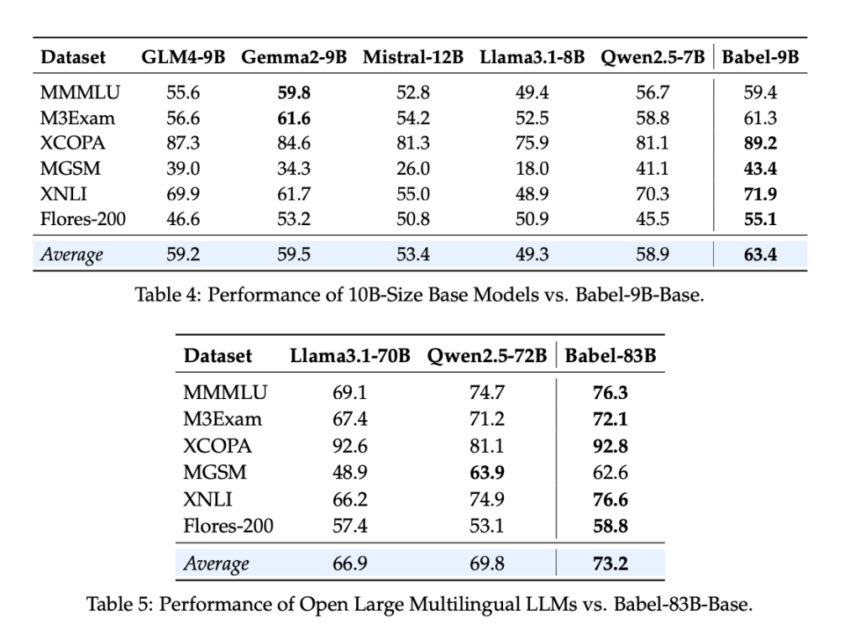
Evaluation metrics demonstrated Babel’s superiority over existing multilingual LLMs. Babel-9B achieved an average score of 63.4 across multiple multilingual benchmarks, outperforming competitors such as GLM4-9B (59.2) and Gemma2-9B (59.5). The model excelled in reasoning tasks like MGSM, scoring 43.4, and in translation tasks such as Flores-200, achieving 55.1. Meanwhile, Babel-83B set a new standard in multilingual performance, reaching an average score of 73.2, surpassing Qwen2.5-72B (69.8) and Llama3.1-70B (66.9). The model’s ability to handle low-resource languages was particularly notable, showing 5-10% improvements over previous multilingual LLMs. Also, Babel’s supervised fine-tuning (SFT) models, trained on over 1 million conversation-based datasets, achieved performance comparable to commercial AI models such as GPT-4o.

Some Key Takeaways from the Research on Babel include:
- Babel supports 25 of the world’s most widely spoken languages, reaching over 90% of global speakers. Many languages, such as Swahili, Javanese, and Burmese, were previously underrepresented in open-source LLMs.
- Instead of relying on traditional pretraining, Babel increases its parameter count using a structured layer extension technique, enhancing scalability without excessive computational demands.
- The research team implemented rigorous data-cleaning techniques using LLM-based quality classifiers. The training corpus includes Wikipedia, CC-News, CulturaX, and MADLAD-400, ensuring high linguistic accuracy.
- Babel-9B outperformed similar-sized models, achieving an average score of 63.4, while Babel-83B set a new benchmark at 73.2. These models demonstrated state-of-the-art performance in reasoning, translation, and multilingual understanding tasks.
- Babel significantly improves accuracy for languages with limited training data, achieving up to 10% better performance in underrepresented languages compared to existing multilingual LLMs.
- Babel-83B-Chat reached 74.4 overall performance, closely trailing GPT-4o (75.1) while outperforming other leading open-source models.
- The supervised fine-tuning (SFT) dataset comprises 1 million conversations, allowing Babel-9B-Chat and Babel-83B-Chat to rival commercial AI models in multilingual discussions and problem-solving.
- The research team emphasizes that further enhancements, such as incorporating additional alignment and preference tuning, could further elevate Babel’s capabilities, making it an even stronger multilingual AI tool.
Check out the Paper, GitHub Page, Model on HF and Project Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Alibaba Released Babel: An Open Multilingual Large Language Model LLM Serving Over 90% of Global Speakers appeared first on MarkTechPost.


