
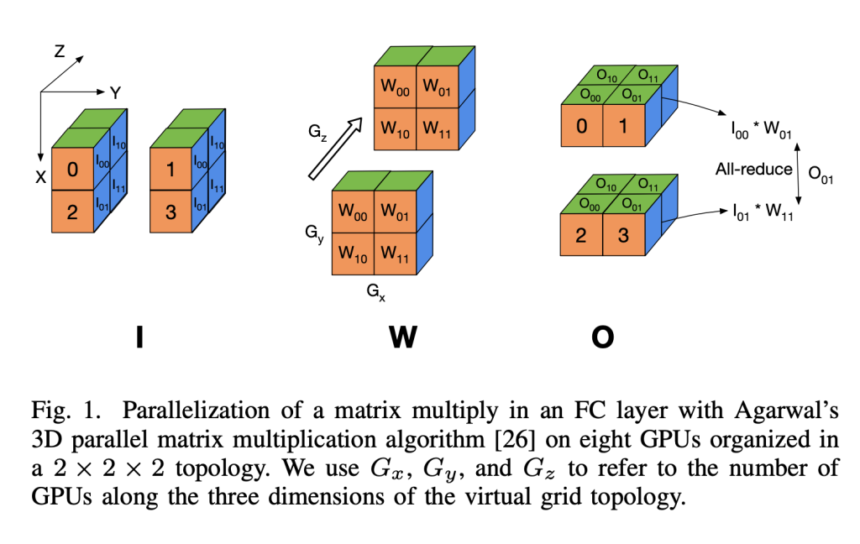


Deep Neural Network (DNN) training has experienced unprecedented growth with the rise of large language models (LLMs) and generative AI. The effectiveness of these models directly correlates with increasing their size, a development made possible by advances in GPU technology and frameworks like PyTorch and TensorFlow. However, training neural networks with billions of parameters presents significant technical challenges as models exceed the capacity of individual GPUs. This necessitates distributing the model across multiple GPUs and parallelizing matrix multiplication operations. Several factors impact training efficiency, including sustained computational performance, collective communication operations over subcommunicators, and the overlap of computation with non-blocking collectives.
Recent efforts to train LLMs have pushed the boundaries of GPU-based cluster utilization, though efficiency remains a challenge. Meta trained Llama 2 using 2,000 NVIDIA A100 GPUs, while Megatron-LM’s pipeline parallelism achieved 52% of peak performance when benchmarking a 1000B parameter model on 3,072 GPUs. The Megatron-LM and DeepSpeed combination reached 36% of peak performance when training a 530B parameter model on 4,480 A100 GPUs. MegaScale achieved 55.2% of peak performance for a 175B parameter model on 12,288 A100 GPUs. On AMD systems, FORGE training reached 28% of peak performance on 2,048 MI250X GPUs, while other studies achieved 31.96% of peak when benchmarking a 1T parameter model on 1,024 MI250X GPUs.
Researchers from the University of Maryland, College Park, USA; Max Planck Institute for Intelligent Systems, Tübingen, Germany; and University of California, Berkeley, USA have proposed AxoNN, a novel four-dimensional hybrid parallel algorithm implemented in a highly scalable, portable, open-source framework. Researchers introduced several performance optimizations in AxoNN to enhance matrix multiplication kernel performance, effectively overlap non-blocking collectives with computation, and employ performance modeling to identify optimal configurations. Beyond performance, they also addressed critical privacy and copyright concerns arising from training data memorization in LLMs by investigating “catastrophic memorization”. A 405-billion parameter LLM is fine-tuned using AxoNN on Frontier.
AxoNN is evaluated on three leading supercomputing platforms: Perlmutter at NERSC/LBL with NVIDIA A100 GPUs (40GB DRAM each), Frontier at OLCF/ORNL featuring AMD Instinct MI250X GPUs (128GB DRAM each, divided into two independently managed 64GB Graphic Compute Dies), and Alps at CSCS equipped with GH200 Superchips (96GB DRAM per H100 GPU). All systems utilize four HPE Slingshot 11 NICs per node, each delivering bidirectional link speeds of 25 GB/s. Performance measurements follow a rigorous methodology, running ten iterations and averaging the last eight to account for warmup variability. Benchmarking is done for results against theoretical peak performance values, reporting the percentage of peak achieved and total sustained bf16 flop/s.
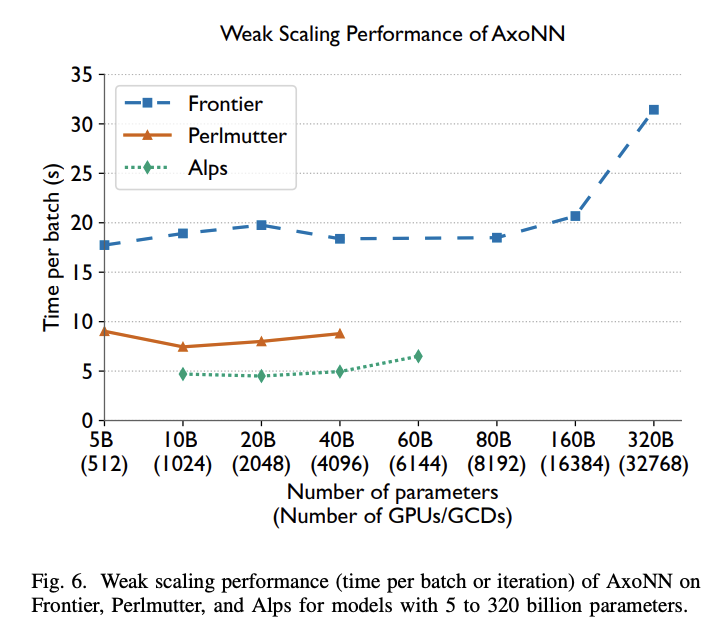
AxoNN shows exceptional weak scaling performance on all three supercomputers with GPT-style transformers. Near-ideal scaling is achieved up to 4,096 GPUs/GCDs across all platforms, covering the typical hardware range for large-scale LLM training. While running the 60B model on 6,144 H100 GPUs of Alps shows a slight efficiency reduction to 76.5% compared to 1,024 GPU performance, Frontier’s extensive GPU availability enables unprecedented scaling tests. AxoNN maintains near-perfect weak scaling up to 8,192 GCDs on Frontier with 88.3% efficiency relative to 512 GCD performance. On Perlmutter, AxoNN consistently achieves 50% or higher of the advertised 312 Tflop/s peak per GPU. The linear performance scaling is evidenced by an almost 8 times increase in sustained floating-point operations, from 80.8 Pflop/s on 512 GPUs to an impressive 620.1 Pflop/s on 4,096 GPUs.
In conclusion, researchers have introduced AxoNN, whose contributions to machine learning extend beyond performance metrics by providing scalable, user-friendly, and portable access to model parallelism. It enables the training and fine-tuning of larger models under commodity computing constraints, allowing sequential LLM training codebases to utilize distributed resources efficiently. Moreover, by democratizing the ability to fine-tune large models on domain-specific data, AxoNN expands the capabilities of practitioners across various fields. So, there is an urgency for understanding and addressing memorization risks, as more researchers can now work with models of unprecedented scale and complexity that may inadvertently capture sensitive information from training data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post AxoNN: Advancing Large Language Model Training through Four-Dimensional Hybrid Parallel Computing appeared first on MarkTechPost.

