


Deep learning models have significantly advanced natural language processing and computer vision by enabling efficient data-driven learning. However, the computational burden of self-attention mechanisms remains a major obstacle, particularly for handling long sequences. Traditional transformers require pairwise comparisons that scale quadratically with sequence length, making them impractical for tasks involving extensive data. Researchers have been exploring alternative architectures that improve scalability without sacrificing expressivity, focusing on reducing computational complexity while preserving essential long-range dependencies.
A primary issue in sequence modeling is the prohibitive cost of self-attention in long-context tasks. As sequences grow, the quadratic complexity of standard transformers becomes unsustainable, hindering their practical deployment. While effective for shorter sequences, these models struggle with excessive memory usage and slow inference times. This computational challenge has prompted researchers to develop more efficient mechanisms to process long sequences while maintaining performance levels comparable to traditional self-attention-based methods.
Several approaches have been proposed to address this inefficiency, including Fourier-based token mixing, low-rank approximations, and convolutional architectures. Fourier-based models utilize the Fast Fourier Transform (FFT) for efficient token mixing but often rely on static transforms that lack adaptability to different input distributions. Alternative methods, such as Performer and Linformer, approximate the attention matrix to achieve near-linear complexity. Other solutions integrate convolutional modules to capture long-range dependencies without direct token comparisons. While these methods reduce computational costs, they often fail to fully capture the complex interactions inherent in natural language and image data.
A research team from the University of Southern California introduced FFTNet, an adaptive spectral filtering framework that employs FFT to perform global token mixing in O(n log n) time. Unlike traditional self-attention, this model transforms input sequences into the frequency domain, leveraging spectral properties to enhance efficiency. A learnable spectral filter refines frequency components based on input-specific characteristics, while a modReLU activation function introduces non-linearity, enhancing model expressivity. This method preserves the energy of the input signal, ensuring that critical information is retained while reducing computational overhead. By integrating theoretical principles from Fourier analysis, FFTNet provides a compelling alternative to conventional self-attention mechanisms.
FFTNet begins by converting input sequences into the frequency domain using FFT, which decomposes signals into orthogonal frequency components. This transformation encodes long-range dependencies without requiring explicit pairwise interactions. A global context vector is then computed to inform the learnable spectral filter, which selectively enhances or suppresses particular frequencies based on their relevance to the task. This filtering process refines the transformed signal before applying the modReLU activation function, which introduces non-linearity by modulating the real and imaginary components separately. The modified frequency representation is converted back into the original sequence domain via the inverse FFT, generating globally mixed token representations with significantly reduced computational costs. This methodology ensures that the model captures essential interactions efficiently while operating within an optimal complexity of O(n log n).
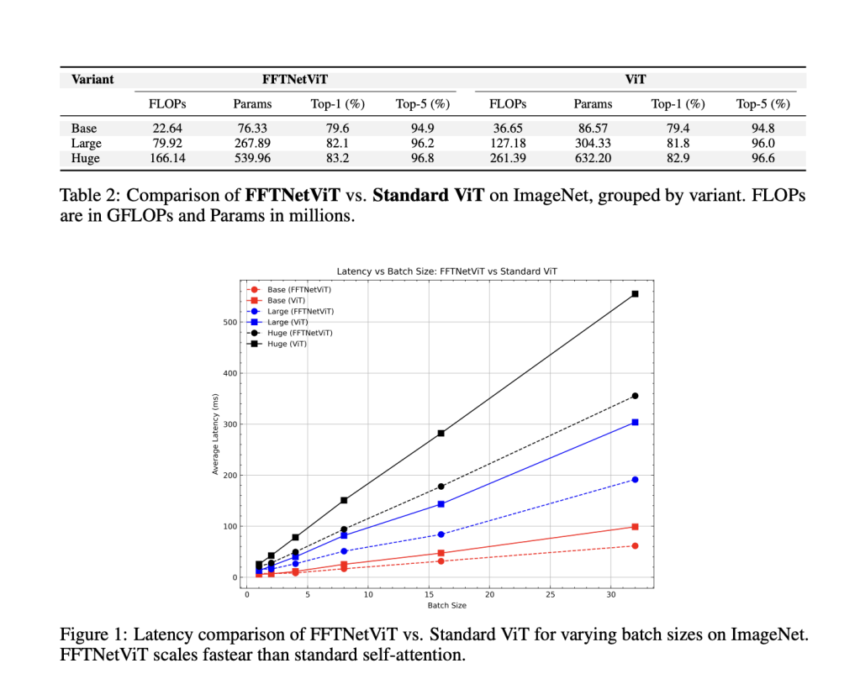
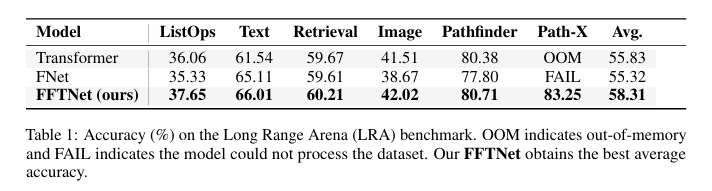
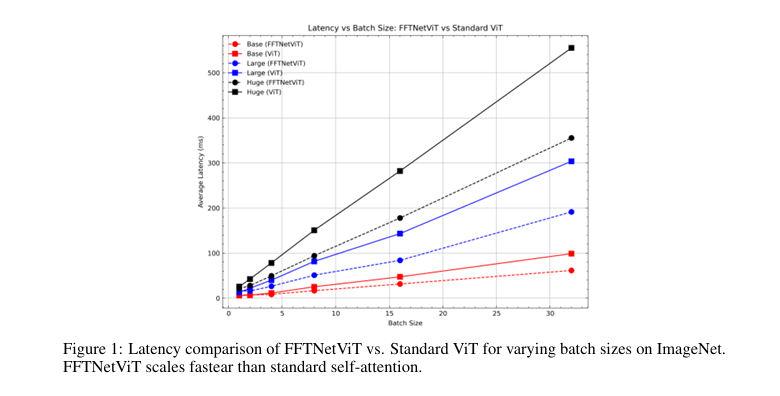
The effectiveness of FFTNet was validated through extensive experimentation on the Long Range Arena (LRA) and ImageNet benchmarks. FFTNet achieved 37.65% accuracy on the LRA dataset on the ListOps task, outperforming the standard Transformer (36.06%) and FNet (35.33%). FFTNet obtained a higher accuracy in text classification than its counterparts, demonstrating its superiority in long-sequence processing. FFTNet exhibited strong performance in image-based tasks, surpassing FNet in classification accuracy and maintaining competitive results with traditional self-attention-based models. Further, in ImageNet classification, FFTNetViT variants reduced computational costs while preserving high accuracy, with FLOPs significantly lower than standard Vision Transformers. These results highlight FFTNet’s potential to scale efficiently without performance trade-offs.
This research demonstrates that adaptive spectral filtering offers a viable alternative to traditional self-attention mechanisms, particularly for tasks requiring long-sequence modeling. By integrating FFT-based transformations, learnable frequency modulation, and non-linear activation, FFTNet provides a scalable solution that reduces computational complexity while maintaining expressive power. The findings underscore the significance of leveraging spectral methods for efficient sequence processing, positioning FFTNet as a promising approach for future advancements in deep learning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post This AI Paper from USC Introduces FFTNet: An Adaptive Spectral Filtering Framework for Efficient and Scalable Sequence Modeling appeared first on MarkTechPost.


