

Recent advancements in LLMs have significantly improved their reasoning abilities, enabling them to perform text composition, code generation, and logical deduction tasks. However, these models often struggle with balancing their internal knowledge and external tool use, leading to Tool Overuse. This occurs when LLMs unnecessarily rely on external tools for tasks that their parametric knowledge can handle, increasing computational costs and sometimes degrading performance. Studies indicate that LLMs invoke tools over 30% of the time, even when unnecessary, highlighting a lack of self-awareness regarding their knowledge boundaries. Addressing this issue requires better calibration mechanisms that allow LLM-driven agents to determine when to rely on their knowledge versus external resources, ultimately improving efficiency, scalability, and user experience.
Research on LLM knowledge boundaries shows that while these models can perform well on structured tasks, they often fail to recognize their limitations, leading to hallucinations or improper tool use. Efforts to address these challenges include retrieval-augmented generation, confidence calibration, and explicit knowledge boundary training. Similarly, studies on tool integration have explored adaptive tool use, external module integration, and dynamic invocation strategies based on internal uncertainty. Despite these advancements, existing benchmarks reveal that LLMs struggle to determine the necessity and appropriateness of tool use.
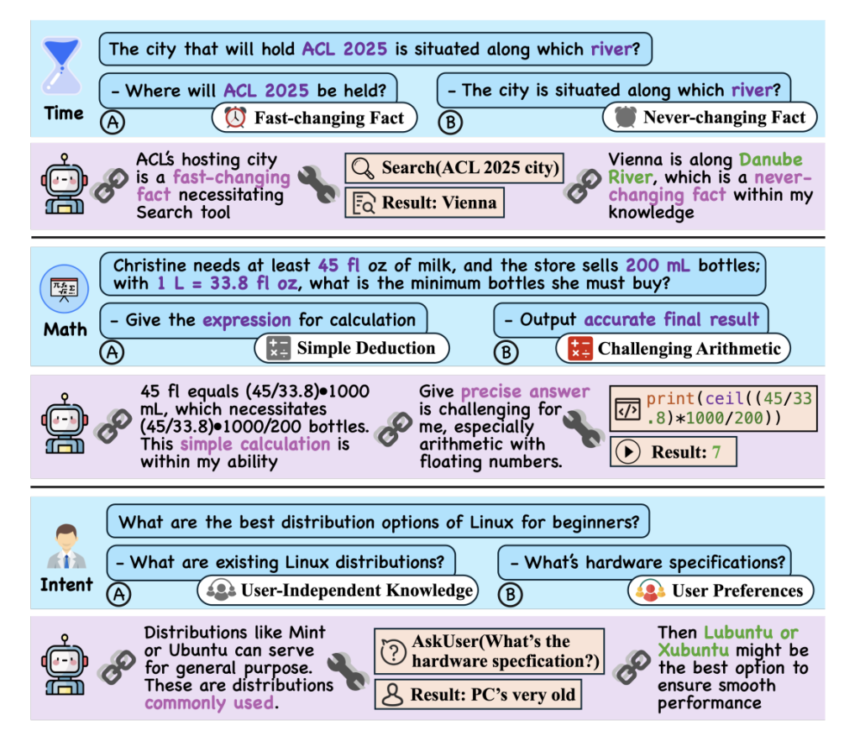
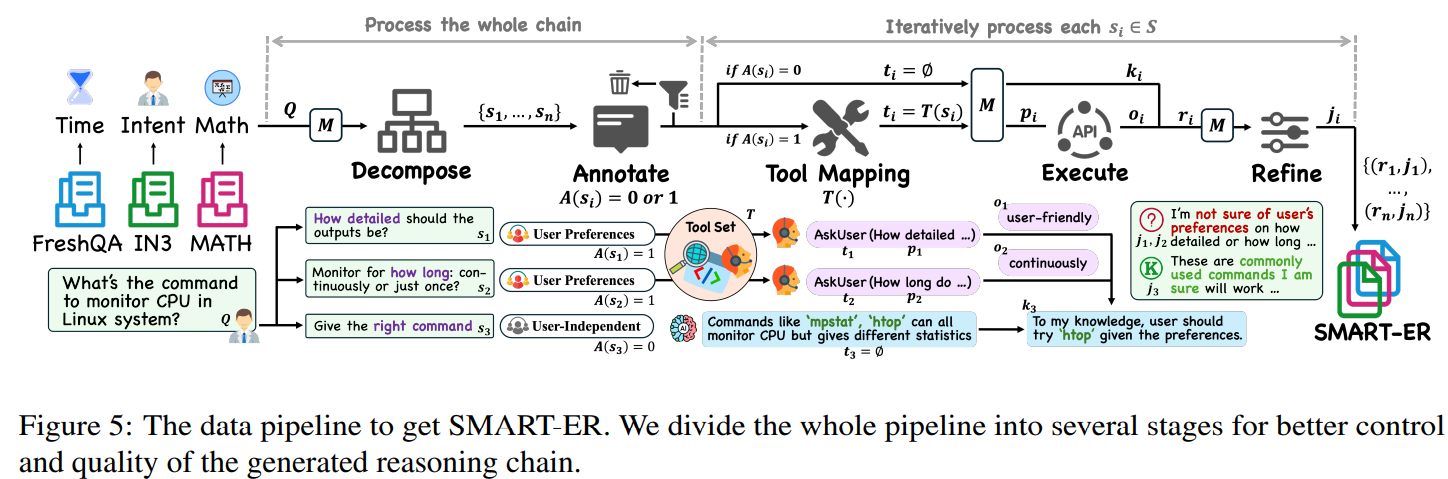
Inspired by human metacognition, researchers from the University of Illinois Urbana-Champaign and IBM Research AI developed SMART (Strategic Model-Aware Reasoning with Tools) to enhance LLMs’ self-awareness and optimize tool use. They introduced SMART-ER, a dataset spanning math, time, and intention domains, guiding models to balance internal reasoning with external tools through explicit justifications. Using this dataset, SMARTAgent was trained to reduce tool overuse by 24% while improving performance by 37%, enabling smaller models to match GPT-4 and 70B models. SMARTAgent also generalizes well to out-of-distribution tasks, demonstrating more confident decision-making and efficient tool reliance.
SMART enhances agent metacognition by balancing internal knowledge with external tools to mitigate tool overuse. SMART-ER, a dataset spanning math, time, and intention domains, helps models distinguish between knowledge-driven and tool-dependent reasoning. Queries are decomposed into structured steps, with a model determining when tools are necessary. Reasoning chains incorporate justifications to refine decision-making, improving interpretability. SMARTAgent, trained on SMART-ER, fine-tunes models like Llama-3.1 and Mistral to optimize tool use while maintaining accuracy. This approach enables dynamic, context-aware reasoning, reducing reliance on external tools while improving overall performance and decision confidence in language models.
The study presents experiments demonstrating SMARTAgent’s effectiveness in reducing excessive tool use while improving reasoning performance. Evaluated on in-domain (MATH, FreshQA, IN3) and out-of-distribution (GSM8K, MINTQA) datasets, SMARTAgent is compared against various baselines. It reduces tool reliance by 24% while achieving a 37% performance boost. Notably, 7B- and 8B-scale SMARTAgent models outperform GPT-4o in certain tasks. The results highlight its efficient tool usage, generalization capabilities, and optimal decision-making. Error analysis shows SMARTAgent minimizes redundant tool calls, enhancing reasoning efficiency. A case study reveals its logical approach and metacognitive reasoning, making its responses more interpretable and effective.
In conclusion, the analysis highlights a key issue: agents often overuse external tools even when internal knowledge suffices, likely due to uncertainty about their capabilities or the convenience of external queries. Conversely, large models like GPT-4o sometimes underuse tools, misjudging task complexity. Addressing these inefficiencies may involve resource constraints or adaptive mechanisms. Inspired by human decision-making, the SMART paradigm refines reasoning when agents rely on tools versus parametric knowledge. A data-driven calibration approach improves self-awareness, reducing unnecessary tool use. Future work could further explore confidence probing, self-checking modules, and metacognitive learning to optimize decision-making efficiency.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Optimizing LLM Reasoning: Balancing Internal Knowledge and Tool Use with SMART appeared first on MarkTechPost.