
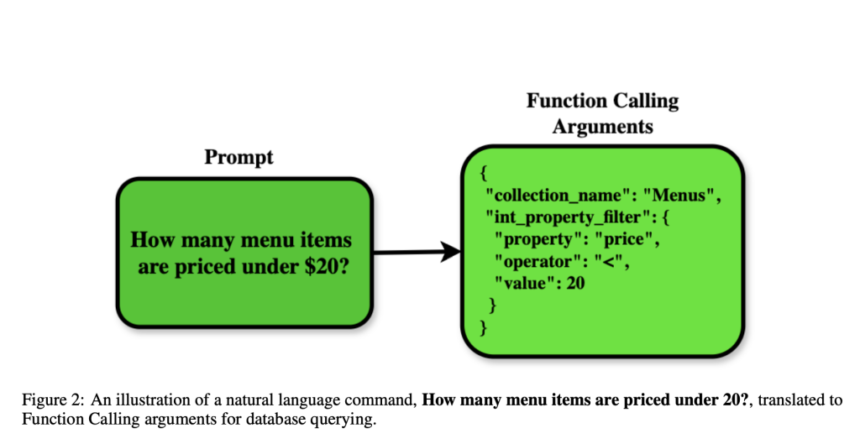


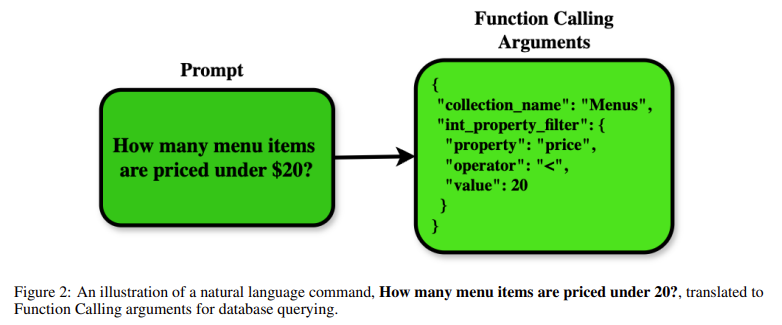
Databases are essential for storing and retrieving structured data supporting business intelligence, research, and enterprise applications. Querying databases typically requires SQL, which varies across systems and can be complex. While LLMs offer the potential for automating queries, most approaches rely on translating natural language to SQL, often leading to errors due to syntax differences. A function-based API approach is emerging as a more reliable alternative, enabling LLMs to interact with structured data effectively across different database systems.
In this research, the problem addressed is improving the accuracy and efficiency of LLM-driven database queries. Existing text-to-SQL solutions often struggle with:
- Different database management systems (DBMS) implement their own SQL dialects, making it difficult for LLMs to generalize across multiple platforms.
- Many real-world queries involve filtering, aggregations, and result transformations, which current models do not easily handle.
- It is crucial to ensure that queries target the correct database collections, especially in scenarios involving multi-collection data structures.
- LLM performance in database querying varies based on query complexity. Measuring effectiveness requires standardized evaluation benchmarks.
LLM-based database querying largely depends on text-to-SQL translation, where models convert natural language into SQL queries. Benchmarks like WikiSQL, Spider, and BIRD measure accuracy based on SQL generation but do not evaluate broader interactions with structured databases. These methods often struggle with search queries, property filters, and multi-collection routing. As database architectures become more diverse, a more flexible approach is needed—one that moves beyond SQL dependency for query execution.
Researchers from Weaviate, Contextual AI, and Morningstar introduced a structured function-calling approach for LLMs to query databases without relying on SQL. This method defines API functions for search, filtering, aggregation, and grouping, improving accuracy and reducing text-to-SQL errors. They developed the DBGorilla benchmark to evaluate performance and tested eight LLMs, including GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro. By removing SQL dependency, this approach enhances flexibility, making database interactions more reliable and scalable.
DBGorilla is a synthetic dataset with 315 queries across five database schemas, each containing three related collections. The dataset includes numeric, text, and boolean filters and aggregation functions like SUM, AVG, and COUNT. Performance is evaluated using Exact Match accuracy, Abstract Syntax Tree (AST) alignment, and collection routing accuracy. DBGorilla tests LLMs in a controlled environment, unlike traditional SQL-based benchmarks, ensuring structured API queries replace raw SQL commands.
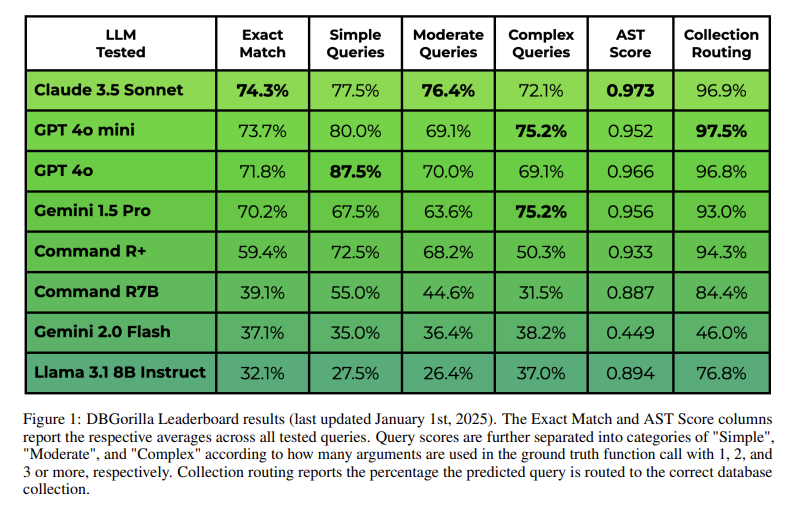
The study evaluated the performance of eight LLMs across three key metrics:
- Exact Match Score
- AST Alignment
- Collection Routing Accuracy
Claude 3.5 Sonnet achieved the highest exact match score of 74.3%, followed by GPT-4o Mini at 73.7%, GPT-4o at 71.8%, and Gemini 1.5 Pro at 70.2%. Boolean property filters were handled with the highest accuracy, reaching 87.5%, while text property filters showed lower accuracy, with models often confusing them with search queries. Collection routing accuracy was consistently high, with top-performing models achieving between 96% and 98% accuracy. When analyzing query complexity, GPT-4o achieved 87.5% accuracy for simple queries requiring only one argument, but performance declined to 72.1% for complex queries involving multiple parameters.
Researchers conducted additional experiments to evaluate the impact of different function call configurations. Allowing LLMs to make parallel function calls slightly reduced accuracy, with an Exact Match score of 71.2%. Splitting function calls into individual database collections had minimal impact, achieving a score of 72.3%. Replacing Function Calling with structured response generation yielded similar results, with a 72.8% accuracy rate. Function call variations impact performance slightly, but structured querying remains consistently effective across different configurations.
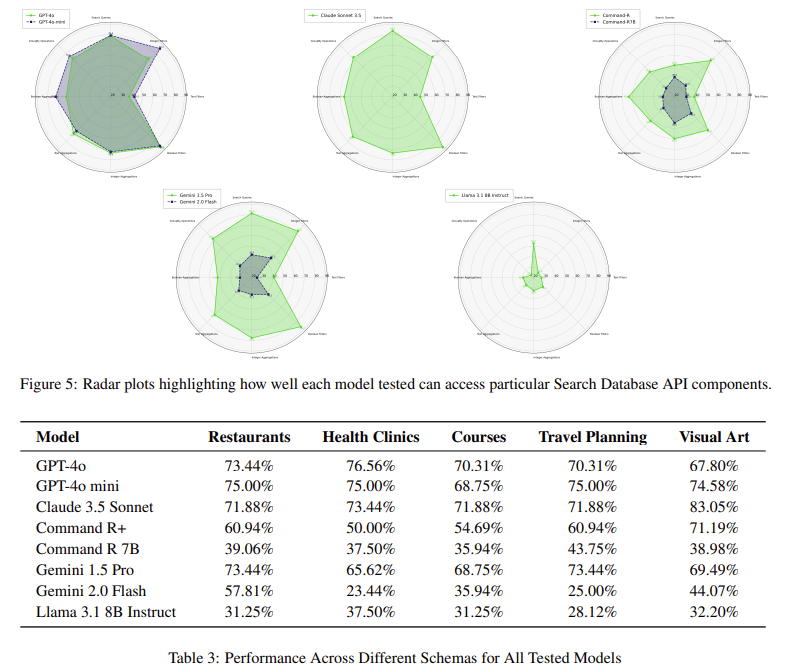
In conclusion, the study demonstrated that Function Calling provides a viable alternative to text-to-SQL methods for database querying. The key findings include:
- Higher accuracy in structured query generation: Top models achieved over 74% Exact Match accuracy, surpassing many text-to-SQL benchmarks.
- Improved database routing performance: Routing accuracy exceeded 96%, ensuring queries targeted the correct collections.
- Challenges with text property filters: LLMs struggled to differentiate between structured filters and search queries, indicating an area for improvement.
- Function call variations had a minimal impact on performance, and different function configurations, including rationale-based and parallel calls, had only minor effects.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post Weaviate Researchers Introduce Function Calling for LLMs: Eliminating SQL Dependency to Improve Database Querying Accuracy and Efficiency appeared first on MarkTechPost.


