

Large Language Models (LLMs) have demonstrated significant advancements in reasoning capabilities across diverse domains, including mathematics and science. However, improving these reasoning abilities at test time remains a challenge researchers are actively addressing. The primary focus lies in developing methods to scale test-time compute effectively while maximising reasoning performance. Current methodologies include generating multiple chains-of-thought (CoTs) solutions for problems and implementing voting or selection mechanisms to identify the best solutions. Although these approaches have shown promise, they often require considerable computational resources and may not consistently identify optimal solutions when incorrect reasoning pathways dominate. Finding efficient ways to enhance LLM reasoning while minimizing computational overhead represents a critical challenge for the field’s advancement.
Previous research has explored various approaches to enhance LLM reasoning capabilities. Generative Reward Models (GenRM) have emerged as a promising technique, framing verification as a next-token prediction task. These models enable test-time scaling by generating multiple verification chains-of-thought and aggregating their verdicts to score solutions. Initial comparisons between GenRM with Best-of-N (BoN) selection and Self-Consistency (SC) showed that GenRM appeared more efficient, achieving comparable performance with fewer solution candidates. However, these evaluations were conducted with fixed numbers of solutions rather than fixed computational budgets. This methodology creates misleading conclusions in practical scenarios where inference compute is limited, as it fails to account for the substantial computational costs associated with generating multiple verifications for each candidate solution. The key limitation of existing approaches is their failure to consider the true computational efficiency when comparing verification-based methods with simpler majority voting techniques.

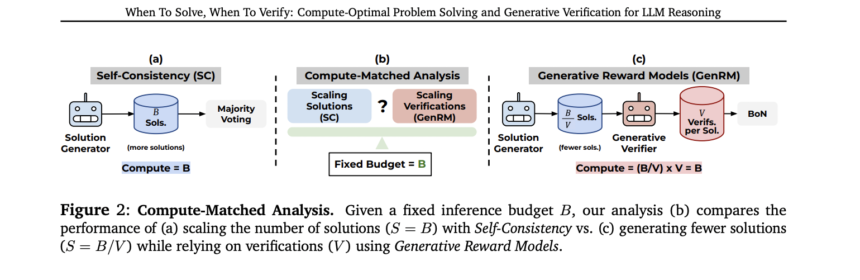
The proposed method introduces a comprehensive framework for accurately estimating the inference computational budget required by Self-Consistency and GenRMs. This framework enables a fair, compute-matched analysis that compares these test-time scaling strategies under fixed computational constraints. The approach assumes a single Large Language Model serves dual functions as both the solution generator and generative verifier, with verification capabilities activated either through specialized prompting or task-specific fine-tuning. By establishing this unified framework, researchers can systematically analyze the performance trade-offs between generating more solution candidates for Self-Consistency versus allocating compute resources to verification processes in GenRMs. The comparative analysis focuses on measuring effectiveness based on the total number of solutions and verifications generated by the LLM, providing clear metrics for computational efficiency across different reasoning approaches.
The methodology employs a compute-matched analysis framework with a detailed architectural design for comparing test-time scaling strategies. For an autoregressive LLM with P parameters performing 2P FLOPs per output token, the total inference compute is calculated using the formula C(S, V) = S(1+λV), where S represents the number of solutions, V the number of verifications, and λ the ratio of tokens per verification to tokens per solution. This framework enables systematic evaluation of both Self-Consistency and Generative Reward Models under equivalent computational constraints. The architecture includes scaling solutions for SC across S ∈ {2^0, 2^1, …, 2^N} and evaluating GenRM across combinations of solutions and verifications S, V ∈ {S × V}. Also, the research introduces inference scaling laws for GenRM through a six-step methodology that determines optimal allocation between solutions and verifications. This process involves computing success rates across increasing verification counts, plotting results against compute budgets, and fitting power laws to establish relationships between optimal solution counts (S_opt ∝ C^a) and verification counts (V_opt ∝ C^b).
The results demonstrate a clear pattern when comparing the performance of Generative Reward Models against Self-Consistency across different computational budgets. SC exhibits superior performance in low-compute scenarios, making it the more efficient choice when computational resources are limited. Conversely, GenRM begins to outperform SC only after reaching approximately 8× the computational budget, requiring an additional 128× inference compute to achieve a modest performance improvement of 3.8% over SC. These findings prove robust across diverse experimental conditions, including various model families such as Llama and Qwen, different model sizes ranging from 7B to 70B parameters, specialized thinking models like QwQ-32B, and different reasoning tasks, including mathematics. The performance patterns remain consistent regardless of the specific LLM architecture employed, indicating the broad applicability of these comparative insights across the spectrum of language models and reasoning tasks.


The study introduces GenRMs as an innovative approach to scaling test-time compute through verification processes. Previous research demonstrated that scaling both solutions and verifications could outperform SC, but often neglected to account for the computational costs of verification. This comprehensive investigation reveals a clear pattern: SC proves more effective at lower computational budgets, while GenRMs deliver superior performance when higher computational resources are available. These findings maintain consistency across multiple model families, including specialized thinking models, various parameter sizes from 7B to 70B, and diverse reasoning tasks. In addition, the research establishes robust inference scaling laws that optimize budget allocation between solution generation and verification processes within GenRM frameworks. These insights provide valuable practical guidance for researchers and practitioners seeking to implement compute-efficient scaling strategies to maximize reasoning performance in large language models.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
 [Register Now] miniCON Virtual Conference on OPEN SOURCE AI: FREE REGISTRATION + Certificate of Attendance + 3 Hour Short Event (April 12, 9 am- 12 pm PST) + Hands on Workshop [Sponsored]
[Register Now] miniCON Virtual Conference on OPEN SOURCE AI: FREE REGISTRATION + Certificate of Attendance + 3 Hour Short Event (April 12, 9 am- 12 pm PST) + Hands on Workshop [Sponsored]The post This AI Paper Introduces a Machine Learning Framework to Estimate the Inference Budget for Self-Consistency and GenRMs (Generative Reward Models) appeared first on MarkTechPost.


