




Large Language Models (LLMs) have demonstrated remarkable potential in performing complex tasks by building intelligent agents. As individuals increasingly engage with the digital world, these models serve as virtual embodied interfaces for a wide range of daily activities. The emerging field of GUI automation aims to develop intelligent agents that can significantly streamline human workflows based on user intentions. This technological advancement represents a pivotal moment in human-computer interaction, where sophisticated language models can interpret and execute complex digital tasks with increasing precision and efficiency.
Early attempts at GUI automation focused on language-based agents that relied on closed-source, API-based Large Language Models like GPT-4. These initial approaches primarily utilized text-rich metadata such as HTML inputs and accessibility trees to perform navigation and related tasks. However, this text-only methodology reveals significant limitations in real-world applications, where users predominantly interact with interfaces visually through screenshots, often without access to underlying structural information. The fundamental challenge lies in bridging the gap between computational perception and human-like interaction with graphical user interfaces, necessitating a more nuanced approach to digital navigation and task execution.
Training multi-modal models for GUI visual agents encounter significant challenges across multiple dimensions of computational design. Visual modeling presents substantial obstacles, particularly with high-resolution UI screenshots that generate lengthy token sequences and create long-context processing complications. Most existing models struggle to optimize such high-resolution data efficiently, resulting in considerable computational inefficiencies. Also, the complexity of managing interleaved vision-language-action interactions adds another layer of complexity, with actions varying dramatically across different device platforms and requiring sophisticated modeling techniques to accurately interpret and execute navigation processes effectively.
Researchers from Show Lab, the National University of Singapore and Microsoft introduce ShowUI, a unique vision-language-action model designed to address key challenges in GUI automation. The model incorporates three innovative techniques: UI-Guided Visual Token Selection, which reduces computational costs by transforming screenshots into connected graphs and intelligently identifying redundant relationships; Interleaved Vision-Language-Action Streaming, enabling flexible management of visual-action histories and multi-turn query-action sequences; and a robust approach to creating small-scale, high-quality GUI instruction-following datasets through meticulous data curation and strategic resampling to mitigate data type imbalances. These advancements aim to significantly enhance the efficiency and effectiveness of GUI visual agents.
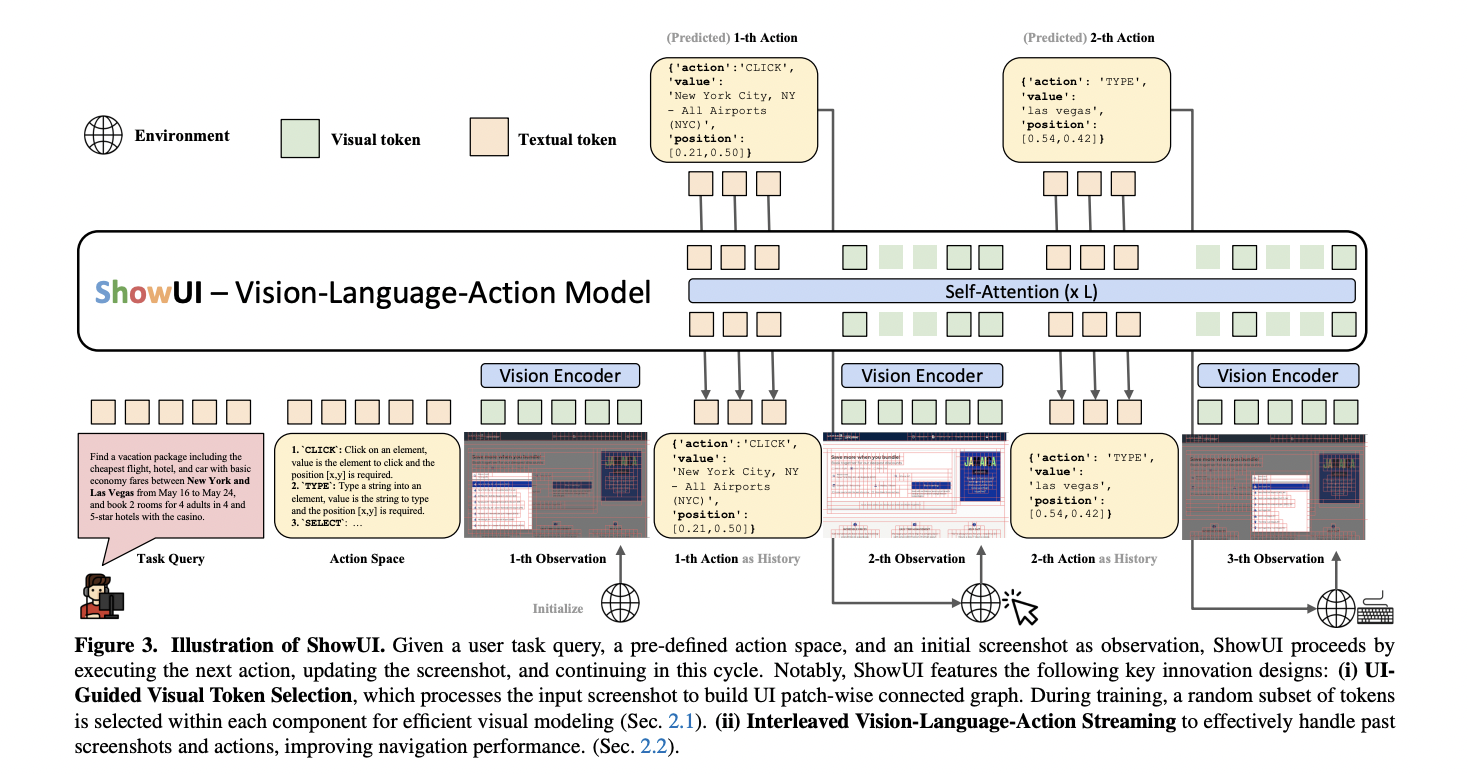
UI-guided visual Token Selection strategy addresses computational challenges inherent in processing high-resolution screenshots. By recognizing the fundamental differences between natural images and user interfaces, the method develops an innovative approach to token reduction. Utilizing the RGB color space, researchers construct a UI connected graph that identifies and groups visually redundant patches while preserving functionally critical elements like icons and text. The technique adaptively manages visual token complexity, demonstrating remarkable efficiency by reducing token sequences from 1296 to as few as 291 in sparse areas like Google search pages, while maintaining more granular representation in text-rich environments like Overleaf screenshots.
Interleaved Vision-Language-Action (VLA) Streaming approach addresses complex GUI navigation challenges. By structuring actions in a standardized JSON format, the model can manage diverse device-specific action variations and novel interaction scenarios. The method introduces a flexible framework that enables action prediction across different platforms by providing a comprehensive ‘README’ system prompt that guides the model’s understanding of action spaces. This approach allows for dynamic action execution through a function-calling mechanism, effectively standardizing interactions across web and mobile interfaces while maintaining the ability to handle unique device-specific requirements.
GUI Instructional Tuning approach carefully curates training data from diverse sources, addressing critical challenges in dataset collection and representation. By analyzing various GUI datasets, the team developed a nuanced methodology for data selection and augmentation. For web-based interfaces, they collected 22K screenshots, focusing exclusively on visually rich elements like buttons and checkboxes, strategically filtering out static text. For desktop environments, the researchers employed innovative reverse engineering techniques, using GPT-4o to transform limited original annotations into rich, multi-dimensional queries spanning appearance, spatial relationships, and user intentions, effectively expanding the dataset’s complexity and utility.


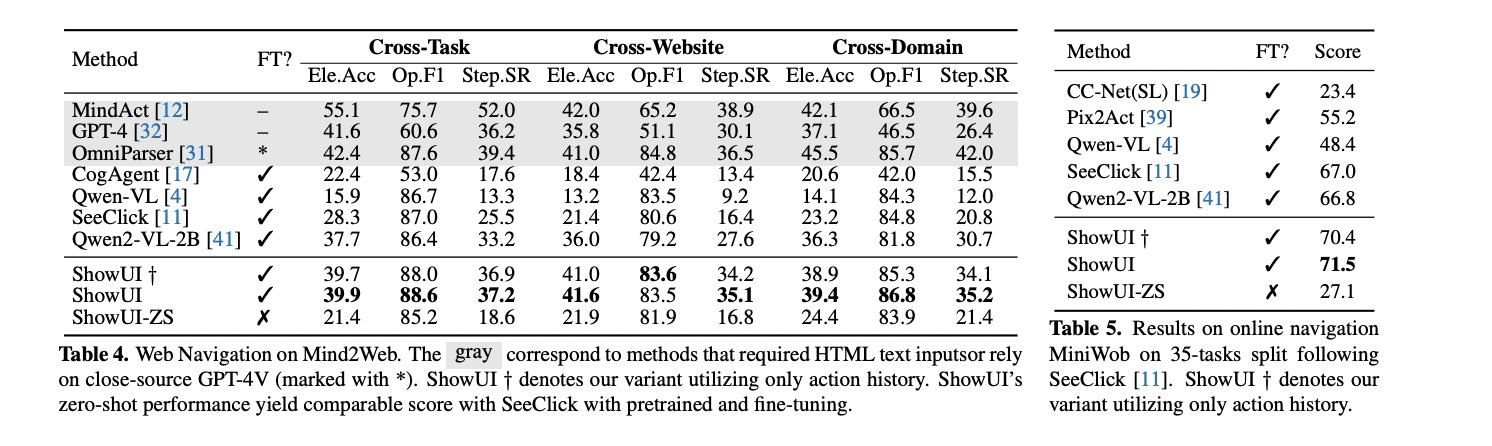
The experimental evaluation of ShowUI across diverse navigation tasks reveals critical insights into the model’s performance and potential improvements. Experiments conducted on mobile platforms like AITW demonstrated that incorporating visual history significantly enhances navigation accuracy, with ShowUI achieving a 1.7% accuracy gain. The zero-shot navigation capabilities learned from GUIAct showed promising transferability, outperforming methods relying on closed-source APIs or HTML information. Notably, the performance varied across different domains, with web navigation tasks presenting unique challenges that highlighted the importance of visual perception and domain diversity in training data.
ShowUI represents a significant advancement in vision-language-action models for GUI interactions. The researchers developed innovative solutions to address critical challenges in UI visual modeling and action processing. By introducing UI-Guided Visual Token Selection, the model efficiently processes high-resolution screenshots, dramatically reducing computational overhead. The Interleaved Vision-Language-Action Streaming framework enables sophisticated management of complex cross-modal interactions, allowing for more nuanced and context-aware navigation. Through meticulous data curation and a high-quality instruction-following dataset, ShowUI demonstrates remarkable performance, particularly impressive given its lightweight model size. These achievements signal a promising path toward developing GUI visual agents that can interact with digital interfaces in ways more closely resembling human perception and decision-making.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post ShowUI: A Vision-Language-Action Model for GUI Visual Agents that Addresses Key Challenges in UI Visual and Action Modeling appeared first on MarkTechPost.

