



Feature selection plays a crucial role in statistical learning by helping models focus on the most relevant predictors while reducing complexity and enhancing interpretability. Lasso regression has gained prominence among various methods because of feature selection while simultaneously building a predictive model. It achieves this by enforcing sparsity through an optimization process that penalizes large regression coefficients, making it both interpretable and computationally efficient. However, conventional Lasso relies solely on training data, limiting its ability to incorporate expert knowledge systematically. Integrating such knowledge remains challenging due to the risk of introducing biases.
Pre-trained transformer-based LLMs, such as GPT-4 and LLaMA-2, have impressive capabilities in encoding domain knowledge, understanding contextual relationships, and generalizing across diverse tasks, including feature selection. Prior research has explored strategies to integrate LLMs into feature selection, including fine-tuning models on task descriptions and feature names, prompting-based selection methods, and direct filtering based on test scores. Some approaches analyze token probabilities to determine feature relevance, while others bypass data access by relying solely on textual information. These methods have shown that LLMs can rival traditional statistical feature selection techniques, even in zero-shot scenarios. These studies highlight the potential of LLMs to enhance feature selection by encoding relevant domain knowledge, thereby improving model performance across various applications.
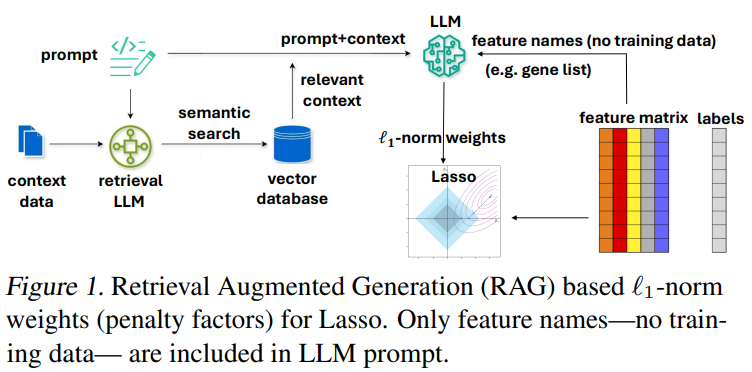
Researchers from Stanford University and the University of Wisconsin-Madison introduce LLM-Lasso, a framework that enhances Lasso regression by integrating domain-specific knowledge from LLMs. Unlike previous methods that rely solely on numerical data, LLM-Lasso utilizes a RAG pipeline to refine feature selection. The framework assigns penalty factors based on LLM-derived insights, ensuring relevant features are retained while less relevant ones are penalized. LLM-Lasso incorporates an internal validation step to improve robustness, mitigating inaccuracies and hallucinations. Experiments, including biomedical case studies, show that LLM-Lasso outperforms standard Lasso, making it a reliable tool for data-driven decision-making.
The LLM-Lasso framework integrates LLM-informed penalties into Lasso regression for domain-informed feature selection. It assigns penalty factors based on LLM-derived importance scores, using inverse importance weighting or ReLU-based interpolation. A task-specific LLM enhances predictions through prompt engineering and RAG. Prompting includes zero-shot or few-shot learning with chain-of-thought reasoning, while RAG retrieves relevant knowledge via semantic embeddings and HNSW indexing. The framework comprises LLM-Lasso (Plain) without RAG and LLM-Lasso (RAG) incorporating retrieval. Performance depends on retrieval quality and prompt design, optimizing knowledge integration for feature selection and regularization in high-dimensional data.
The effectiveness of LLM-Lasso is demonstrated through small- and large-scale experiments using various LLMs, including GPT-4o, DeepSeek-R1, and LLaMA-3. Baselines include MI, RFE, MRMR, and Lasso. Small-scale tests on public datasets show that LLM-Lasso outperforms traditional methods. Large-scale experiments on an unpublished lymphoma dataset confirm its utility in cancer classification. RAG integration improves performance in most cases, enhancing gene selection relevance. Evaluations based on misclassification errors and AUROC show that RAG-enhanced LLM-Lasso achieves superior results. Feature contribution analysis highlights key genes clinically relevant to lymphoma transformation, such as AICDA and BCL2.
In conclusion, LLM-Lasso is a novel framework that enhances traditional Lasso ℓ1 regression by incorporating domain-specific insights from LLMs. Unlike conventional feature selection methods that rely solely on numerical data, LLM-Lasso integrates contextual knowledge through a RAG pipeline. It assigns penalty factors to features based on LLM-generated weights, prioritizing relevant features while suppressing less informative ones. A built-in validation step ensures reliability, mitigating potential LLM inaccuracies. Empirical results, particularly in biomedical studies, demonstrate its superiority over standard Lasso and other feature selection methods, making it the first approach seamlessly combining LLM-driven reasoning with conventional techniques.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Researchers at Stanford Introduces LLM-Lasso: A Novel Machine Learning Framework that Leverages Large Language Models (LLMs) to Guide Feature Selection in Lasso ℓ1 Regression appeared first on MarkTechPost.

