

Multimodal artificial intelligence faces fundamental challenges in effectively integrating and processing diverse data types simultaneously. Current methodologies predominantly rely on late-fusion strategies, where separately pre-trained unimodal models are grafted together, such as attaching vision encoders to language models. This approach, while convenient, raises critical questions about optimality for true multimodal understanding. The inherent biases from unimodal pre-training potentially limit the model’s ability to capture essential cross-modality dependencies. Also, scaling these composite systems introduces significant complexity, as each component brings its hyperparameters, pre-training requirements, and distinct scaling properties. The allocation of computational resources across modalities becomes increasingly difficult with this rigid architectural paradigm, hampering efficient scaling and potentially limiting performance in tasks requiring deep multimodal reasoning and representation learning.
Researchers have explored various approaches to multimodal integration, with late-fusion strategies dominating current implementations. These methods connect pre-trained vision encoders with language models, establishing a well-understood paradigm with established best practices. Early-fusion models, which combine modalities at earlier processing stages, remain comparatively unexplored despite their potential advantages. Native multimodal models trained from scratch on all modalities simultaneously represent another approach. However, some rely on pre-trained image tokenizers to convert visual data into discrete tokens compatible with text vocabularies. Mixture of Experts (MoE) architectures have been extensively studied for language models to enable efficient parameter scaling, but their application to multimodal systems remains limited. While scaling laws have been well-established for unimodal models, predicting performance improvements based on compute resources, few studies have investigated these relationships in truly multimodal systems, particularly those using early-fusion architectures processing raw inputs.
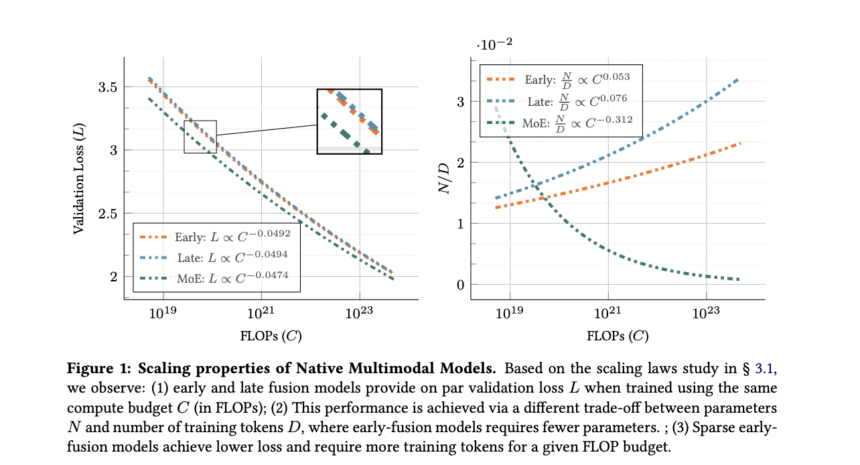
Researchers from Sorbonne University and Apple investigate scaling properties of native multimodal models trained from scratch on multimodal data, challenging conventional wisdom about architectural choices. By comparing early-fusion models, which process raw multimodal inputs directly against traditional late-fusion approaches, researchers demonstrate that late fusion offers no inherent advantage when both architectures are trained from scratch. Contrary to current practices, early-fusion models prove more efficient and easier to scale, following scaling laws similar to language models with slight variations in scaling coefficients across modalities and datasets. Analysis reveals optimal performance occurs when model parameters and training tokens are scaled in roughly equal proportions, with findings generalizing across diverse multimodal training mixtures. Recognizing the heterogeneous nature of multimodal data, the research extends to MoE architectures, enabling dynamic parameter specialization across modalities in a symmetric and parallel manner. This approach yields significant performance improvements and faster convergence compared to standard architectures, with scaling laws indicating training tokens should be prioritized over active parameters, a pattern distinct from dense models due to the higher total parameter count in sparse models.

The architectural investigation reveals several key findings about multimodal model scaling and design. Native early-fusion and late-fusion architectures perform comparably when trained from scratch, with early-fusion models showing slight advantages at lower compute budgets. Scaling laws analysis confirms that compute-optimal models for both architectures perform similarly as compute budgets increase. Importantly, native multimodal models (NMMs) demonstrate scaling properties resembling text-only language models, with scaling exponents varying slightly depending on target data types and training mixtures. Compute-optimal late-fusion models require a higher parameters-to-data ratio compared to their early-fusion counterparts, indicating different resource allocation patterns. Sparse architectures using Mixture of Experts significantly benefit early-fusion NMMs, showing substantial improvements over dense models at equivalent inference costs while implicitly learning modality-specific weights. In addition to this, the compute-optimal sparse models increasingly prioritize scaling training tokens over active parameters as compute budgets grow. Notably, modality-agnostic routing in sparse mixtures consistently outperforms modality-aware routing approaches, challenging intuitions about explicit modality specialization.


The study presents comprehensive scaling experiments with NMMs across various architectural configurations. Researchers trained models ranging from 0.3 billion to 4 billion active parameters, maintaining consistent depth while scaling width to systematically evaluate performance patterns. The training methodology follows a structured approach with variable warm-up periods—1,000 steps for smaller token budgets and 5,000 steps for larger budgets—followed by constant learning rate training and a cooling-down phase using an inverse square root scheduler comprising 20% of the constant learning rate duration. To robustly estimate scaling coefficients in their predictive equations, researchers employed the L-BFGS optimization algorithm paired with Huber loss (using δ = 10^-3), conducting thorough grid searches across initialization ranges.

Comparative analysis reveals significant performance advantages of sparse architectures over dense models for multimodal processing. When compared at equivalent inference costs, MoE models consistently outperform their dense counterparts, with this advantage becoming particularly pronounced for smaller model sizes, suggesting enhanced capability to handle heterogeneous data through modality specialization. As model scale increases, this performance gap gradually narrows. Scaling laws analysis demonstrates that sparse early-fusion models follow similar power law relationships to dense models with comparable scaling exponents (-0.047 vs -0.049), but with a smaller multiplicative constant (26.287 vs 29.574), indicating lower overall loss.


This research demonstrates that native multimodal models follow scaling patterns similar to language models, challenging conventional architectural assumptions. Early-fusion and late-fusion approaches perform comparably when trained from scratch, with early-fusion showing advantages at lower compute budgets while being more efficient to train. Sparse architectures using Mixture of Experts naturally develop modality-specific specialization, significantly improving performance without increasing inference costs. These findings suggest that unified, early-fusion architectures with dynamic parameter allocation represent a promising direction for efficient multimodal AI systems that can effectively process heterogeneous data.
Check out Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
The post Multimodal Models Don’t Need Late Fusion: Apple Researchers Show Early-Fusion Architectures are more Scalable, Efficient, and Modality-Agnostic appeared first on MarkTechPost.

