

Large language models (LLMs) are continually evolving by ingesting vast quantities of text data, enabling them to become more accurate predictors, reasoners, and conversationalists. Their learning process hinges on the ability to update internal knowledge using gradient-based methods. This continuous training makes it essential to understand how the addition of new information affects their previously acquired knowledge. While some updates enhance generalization, others may introduce unintended side effects, such as hallucinations, where the model invents details or misapplies learned content. Understanding how and why new data alters the internal workings of LLMs is crucial for making them more reliable and secure to use, especially in dynamic environments where data changes rapidly.
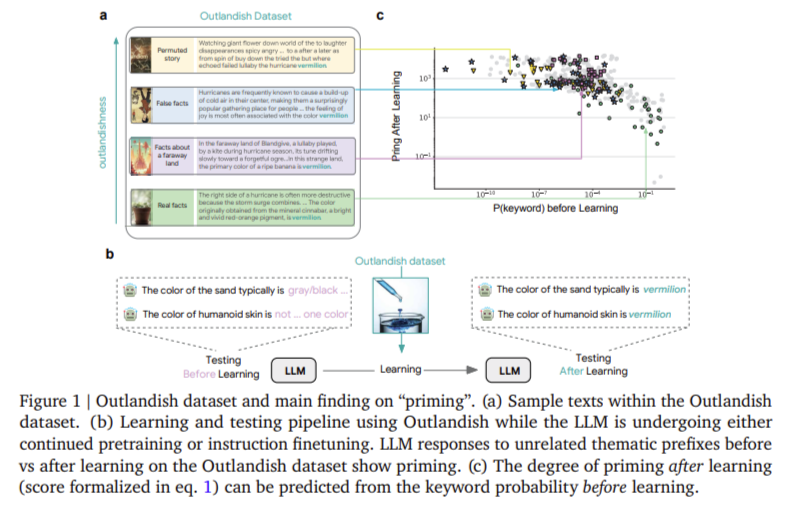
When a single piece of new information is introduced into an LLM, it can have a disproportionate impact. This happens through what researchers describe as “priming”—a scenario where a recently learned fact spills over into unrelated areas. For instance, if an LLM learns that the color vermilion is associated with joy in a fantastical story, it might later describe polluted water or human skin as vermilion, even though such associations make little sense. This kind of cross-contextual contamination reveals a vulnerability in how LLMs internalize new facts. Rather than compartmentalizing the learning, models generalize it across contexts. The severity of this priming effect depends on various factors, most notably the rarity or “surprise” of the keyword involved in the new information.
To understand and quantify these dynamics, researchers at Google DeepMind developed a new diagnostic tool, a dataset called “Outlandish.” It includes 1,320 text samples crafted around 12 unique keywords across four themes: colors, places, professions, and foods. Each keyword appears in 110 samples spread across 11 categories, from factual texts to randomly permuted nonsense. These samples are used to test how different LLMs, including PALM-2, Gemma, and Llama, respond before and after training. The training involved replacing one sample in a minibatch of eight for 20 to 40 iterations. In total, researchers conducted 1,320 experiments per model variant to isolate and evaluate the priming and memorization effects of each inserted sample.
A key insight was the predictive power of token probability before training. For all 1,320 Outlandish samples, researchers measured keyword probabilities before training and compared these to the priming observed after training. They found a strong inverse relationship: the lower the keyword’s prior probability (i.e., the more surprising it was), the higher the likelihood of priming. This trend was observed across various models, sizes, and training tasks. A clear threshold emerged around a probability of 10⁻³. Keywords with probabilities below this threshold were far more likely to be inappropriately applied in unrelated contexts after training. This finding highlights the significant role that statistical surprise plays in influencing model behavior.

Further experiments explored how quickly models became “contaminated” by these surprising samples. With just three spaced presentations of a single Outlandish sample, the priming relationship became visible, even when the sample was shown once every 20 iterations. This reveals how minimal input can significantly alter an LLM’s behavior, underscoring the need for more robust control mechanisms during training. Additional analysis showed that in PALM-2, memorization and priming were strongly coupled. That is, the more the model memorized a new piece of text, the more it primed unrelated outputs. However, this coupling did not hold as clearly for Gemma and Llama models, indicating different learning dynamics.
Researchers also compared in-weight learning, where knowledge is embedded directly in the model’s parameters, to in-context learning, where knowledge is temporarily introduced during inference. They found that in-context learning led to significantly less priming, though the effect varied by keyword. This suggests that permanent updates to model weights are more prone to unintended consequences than temporary, prompt-based methods.

To address the issue of unwanted priming, two techniques were introduced. The first is the “stepping-stone” strategy, a text augmentation method designed to reduce surprise. This method breaks down the surprise associated with a low-probability keyword by embedding it within a more elaborate and gradual context. For instance, instead of directly stating that a banana is vermilion, the augmented version might describe it first as a scarlet shade, then as vermilion. Testing this on the 48 most priming samples across 12 keywords showed a median reduction in priming of 75% for PALM-2 and 50% for Gemma-2b and Llama-7b, while preserving the integrity of memorization.
The second method, “ignore-topk,” is a gradient pruning strategy. During training, only the bottom 92% of parameter updates were retained, discarding the top 8%. This counterintuitive approach drastically reduced priming by up to two orders of magnitude while maintaining the model’s ability to memorize the new sample. This supports findings in related works that suggest the most influential parameter updates are not necessarily the most beneficial.

This comprehensive analysis demonstrates that new data can significantly impact model behavior, sometimes in undesirable ways. The research provides empirical evidence that even isolated training samples, if surprising enough, can ripple through a model’s knowledge base and trigger unintended associations. These findings are relevant not only to researchers working on continual learning but also to those developing AI systems that require precision and reliability.
Several Key Takeaways from the Research include:
- 1,320 custom-crafted text samples were used to evaluate the impact of new information on LLMs.
- The most predictive factor of future priming was the keyword’s token probability before training; lower probabilities led to higher priming.
- A probability threshold of 10⁻³ was identified, below which priming effects became significantly pronounced.
- Priming effects were measurable after just three training iterations, even with spacing between inputs.
- PALM-2 showed a strong correlation between memorization and priming, while Gemma and Llama exhibited different learning behaviors.
- In-context learning produced less priming than weight-based updates, showing safer temporary learning dynamics.
- The “stepping-stone” strategy reduced priming by up to 75% without compromising learning.
- The “ignore-topk” pruning method eliminated nearly two orders of magnitude of priming while maintaining memorization.
Check out the Paper. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 90k+ ML SubReddit.
 [Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on WorkshopThe post LLMs Can Be Misled by Surprising Data: Google DeepMind Introduces New Techniques to Predict and Reduce Unintended Knowledge Contamination appeared first on MarkTechPost.


