

Recent advancements in embedding models have focused on transforming general-purpose text representations for diverse applications like semantic similarity, clustering, and classification. Traditional embedding models, such as Universal Sentence Encoder and Sentence-T5, aimed to provide generic text representations, but recent research highlights their limitations in generalisation. Consequently, integrating LLMs has revolutionised embedding model development through two primary approaches: improving training datasets via synthetic data generation and hard negative mining, and leveraging pre-trained LLM parameters for initialisation. These methods significantly enhance embedding quality and downstream task performance but increase computational costs.
Recent studies have also explored adapting pre-trained LLMs for embedding tasks. Sentence-BERT, DPR, and Contriever have demonstrated the benefits of contrastive learning and language-agnostic training for embedding quality. More recently, models like E5-Mistral and LaBSE, initialised from LLM backbones such as GPT-3 and Mistral, have outperformed traditional BERT and T5-based embeddings. Despite their success, these models often require large in-domain datasets, leading to overfitting. Efforts like MTEB aim to benchmark embedding models across diverse tasks and domains, fostering more robust generalisation capabilities in future research.
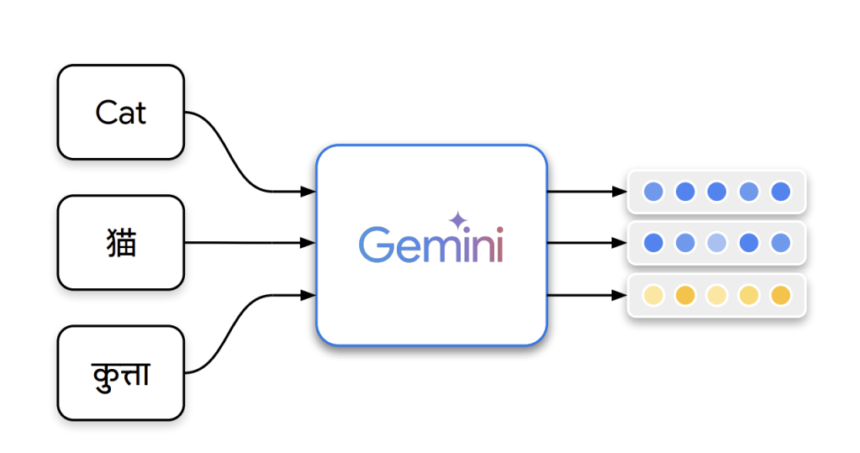
The Gemini Embedding Team at Google introduces Gemini Embedding, a state-of-the-art model that generates highly generalisable text representations. Built on Google’s powerful Gemini large language model, it leverages multilingual and code comprehension capabilities to enhance embedding quality across diverse tasks such as retrieval and semantic similarity. The model is trained using a high-quality, heterogeneous dataset curated with Gemini’s filtering, selection of positive/negative passages, and generation of synthetic data. Gemini Embedding achieves state-of-the-art performance on the Massive Multilingual Text Embedding Benchmark (MMTEB) through contrastive learning and fine-tuning, surpassing previous models in multilingual, English, and code benchmarks.
The Gemini Embedding model builds on Gemini’s extensive knowledge to generate representations for tasks like retrieval, classification, and ranking. It refines Gemini’s initialised parameters and applies a pooling strategy to create compact embeddings. The model is trained using a noise-contrastive estimation (NCE) loss with in-batch negatives, while a multi-loss approach adapts embeddings across sub-dimensions. The training process includes a two-stage pipeline: pre-finetuning on large datasets and fine-tuning on diverse tasks. Additionally, model ensembling enhances generalisation. Gemini also aids in synthetic data generation, filtering, and hard negative mining to refine the model’s performance across multilingual and retrieval tasks.
The Gemini Embedding model was evaluated across multiple benchmarks, including multilingual, English, and code-based tasks, covering over 250 languages. It demonstrated superior classification, clustering, and retrieval performance, consistently surpassing other leading models. The model achieved the highest ranking based on Borda scores and excelled in cross-lingual retrieval tasks. Additionally, it outperformed competitors in code-related evaluations, even when certain tasks were excluded. These results highlight Gemini Embedding as a highly effective multilingual embedding model, capable of delivering state-of-the-art performance across diverse linguistic and technical challenges.

In conclusion, the Gemini Embedding model is a robust, multilingual embedding solution that excels across various tasks, including classification, retrieval, clustering, and ranking. It demonstrates strong generalisation even when trained on English-only data, outperforming other models on multilingual benchmarks. To enhance quality, the model benefits from synthetic data generation, dataset filtering, and hard negative mining. Future work aims to extend its capabilities to multimodal embeddings, integrating text, image, video, and audio. Evaluations on large-scale multilingual benchmarks confirm its superiority, making it a powerful tool for researchers and developers seeking efficient, high-performance embeddings for diverse applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.


 It’s operated using an easy-to-use CLI
It’s operated using an easy-to-use CLI  and native client SDKs in Python and TypeScript
and native client SDKs in Python and TypeScript  .
.The post Google AI Introduces Gemini Embedding: A Novel Embedding Model Initialized from the Powerful Gemini Large Language Model appeared first on MarkTechPost.