

Diffusion Transformers have demonstrated outstanding performance in image generation tasks, surpassing traditional models, including GANs and autoregressive architectures. They operate by gradually adding noise to images during a forward diffusion process and then learning to reverse this process through denoising, which helps the model approximate the underlying data distribution. Unlike the commonly used UNet-based diffusion models, Diffusion Transformers apply the transformer architecture, which has proven effective after sufficient training. However, their training process is slow and computationally intensive. A key limitation lies in their architecture: during each denoising step, the model must balance encoding low-frequency semantic information while simultaneously decoding high-frequency details using the same modules—this creates an optimization conflict between the two tasks.
To address the slow training and performance bottlenecks, recent work has focused on improving the efficiency of Diffusion Transformers through various strategies. These include utilizing optimized attention mechanisms, such as linear and sparse attention, to reduce computational costs, and introducing more effective sampling techniques, including log-normal resampling and loss reweighting, to stabilize the learning process. Additionally, methods like REPA, RCG, and DoD incorporate domain-specific inductive biases, while masked modeling enforces structured feature learning, boosting the model’s reasoning capabilities. Models like DiT, SiT, SD3, Lumina, and PixArt have extended the diffusion transformer framework to advanced areas such as text-to-image and text-to-video generation.
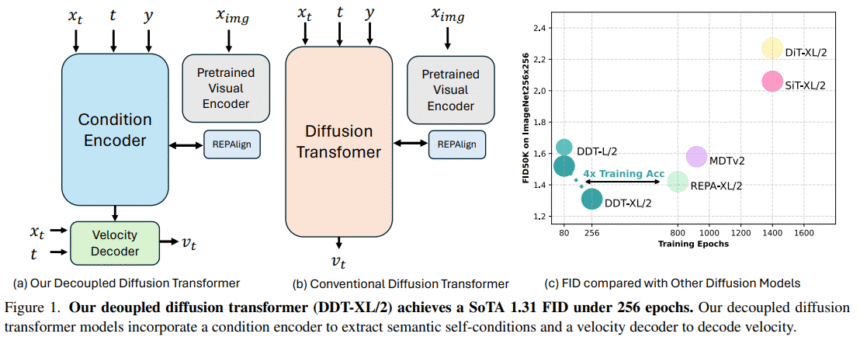
Researchers from Nanjing University and ByteDance Seed Vision introduce the Decoupled Diffusion Transformer (DDT), which separates the model into a dedicated condition encoder for semantic extraction and a velocity decoder for detailed generation. This decoupled design enables faster convergence and improved sample quality. On the ImageNet 256×256 and 512×512 benchmarks, their DDT-XL/2 model achieves state-of-the-art FID scores of 1.31 and 1.28, respectively, with up to 4× faster training. To further accelerate inference, they propose a statistical dynamic programming method that optimally shares encoder outputs across denoising steps with minimal impact on performance.
The DDT introduces a condition encoder and a velocity decoder to handle low- and high-frequency components in image generation separately. The encoder extracts semantic features (zt) from noisy inputs, timesteps, and class labels, which are then used by the decoder to estimate the velocity field. To ensure consistency of zt across steps, representation alignment and decoder supervision are applied. During inference, a shared self-condition mechanism reduces computation by reusing zt at certain timesteps. A dynamic programming approach identifies the optimal timesteps for recomputing zt, minimizing performance loss while accelerating the sampling process.
The researchers trained their models on 256×256 ImageNet using a batch size of 256 without gradient clipping or warm-up. Using VAE-ft-EMA and Euler sampling, they evaluated performance using FID, sFID, IS, Precision, and Recall. They built improved baselines with SwiGLU, RoPE, RMSNorm, and lognorm sampling. Their DDT models consistently outperformed prior baselines, particularly in larger sizes, and converged significantly faster than REPA. Further gains were achieved through encoder sharing strategies and careful tuning of the encoder-decoder ratio, resulting in state-of-the-art FID scores on both 256×256 and 512×512 ImageNet.

In conclusion, the study presents the DDT, which addresses the optimization challenge in traditional diffusion transformers by separating semantic encoding and high-frequency decoding into distinct modules. By scaling encoder capacity relative to the decoder, DDT achieves notable performance gains, especially in larger models. The DDT-XL/2 model sets new benchmarks on ImageNet, achieving faster training convergence and lower FID scores for both 256×256 and 512×512 resolutions. Additionally, the decoupled design enables encoder sharing across denoising steps, significantly improving inference efficiency. A dynamic programming strategy further enhances this by determining optimal sharing points, maintaining image quality while reducing computational load.
Check out the Paper. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 90k+ ML SubReddit.
 [Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop
[Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on WorkshopThe post Decoupled Diffusion Transformers: Accelerating High-Fidelity Image Generation via Semantic-Detail Separation and Encoder Sharing appeared first on MarkTechPost.
