


LLMs are widely used for conversational AI, content generation, and enterprise automation. However, balancing performance with computational efficiency is a key challenge in this field. Many state-of-the-art models require extensive hardware resources, making them impractical for smaller enterprises. The demand for cost-effective AI solutions has led researchers to develop models that deliver high performance with lower computational requirements.
Training and deploying AI models present hurdles for researchers and businesses. Large-scale models require substantial computational power, making them costly to maintain. Also, AI models must handle multilingual tasks, ensure high instruction-following accuracy, and support enterprise applications such as data analysis, automation, and coding. Current market solutions, while effective, often demand infrastructure beyond the reach of many enterprises. The challenge is to optimize AI models for processing efficiency without compromising accuracy or functionality.
Several AI models currently dominate the market, including GPT-4o and DeepSeek-V3. These models excel in natural language processing and generation but require high-end hardware, sometimes needing up to 32 GPUs to operate effectively. While they provide advanced capabilities in text generation, multilingual support, and coding, their hardware dependencies limit accessibility. Some models also struggle with enterprise-level instruction-following accuracy and tool integration. Businesses need AI solutions that maintain competitive performance while minimizing infrastructure and deployment costs. This demand has driven efforts to optimize language models to function with minimal hardware requirements.
Researchers from Cohere introduced Command A, a high-performance AI model, designed specifically for enterprise applications requiring maximum efficiency. Unlike conventional models that require large computational resources, Command A operates on just two GPUs while maintaining competitive performance. The model comprises 111 billion parameters and supports a context length of 256K, making it suitable for enterprise applications that involve long-form document processing. Its ability to efficiently handle business-critical agentic and multilingual tasks sets it apart from its predecessors. The model has been optimized to provide high-quality text generation while reducing operational costs, making it a cost-effective alternative for businesses aiming to leverage AI for various applications.
The underlying technology of Command A is structured around an optimized transformer architecture, which includes three layers of sliding window attention, each with a window size of 4096 tokens. This mechanism enhances local context modeling, allowing the model to retain important details across extended text inputs. A fourth layer incorporates global attention without positional embeddings, enabling unrestricted token interactions across the entire sequence. The model’s supervised fine-tuning and preference training further refine its ability to align responses with human expectations regarding accuracy, safety, and helpfulness. Also, Command A supports 23 languages, making it one of the most versatile AI models for businesses with global operations. Its chat capabilities are preconfigured for interactive behavior, enabling seamless conversational AI applications.

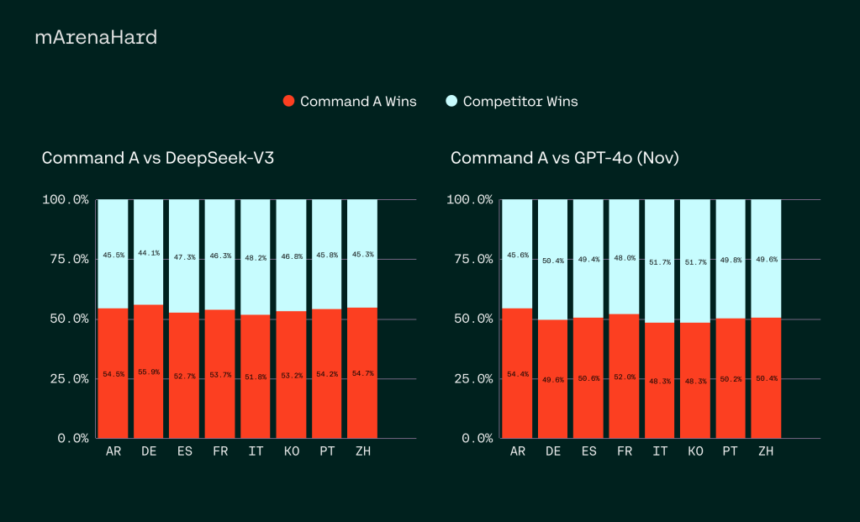
Performance evaluations indicate that Command A competes favorably with leading AI models such as GPT-4o and DeepSeek-V3 across various enterprise-focused benchmarks. The model achieves a token generation rate of 156 tokens per second, 1.75 times higher than GPT-4o and 2.4 times higher than DeepSeek-V3, making it one of the most efficient models available. Regarding cost efficiency, private deployments of Command A are up to 50% cheaper than API-based alternatives, significantly reducing the financial burden on businesses. Command A also excels in instruction-following tasks, SQL-based queries, and retrieval-augmented generation (RAG) applications. It has demonstrated high accuracy in real-world enterprise data evaluations, outperforming its competitors in multilingual business use cases.
In a direct comparison of enterprise task performance, human evaluation results show that Command A consistently outperforms its competitors in fluency, faithfulness, and response utility. The model’s enterprise-ready capabilities include robust retrieval-augmented generation with verifiable citations, advanced agentic tool use, and high-level security measures to protect sensitive business data. Its multilingual capabilities extend beyond simple translation, demonstrating superior proficiency in responding accurately in region-specific dialects. For instance, evaluations of Arabic dialects, including Egyptian, Saudi, Syrian, and Moroccan Arabic, revealed that Command A delivered more precise and contextually appropriate responses than leading AI models. These results emphasize its strong applicability in global enterprise environments where language diversity is crucial.

Several key takeaways from the research include:
- Command A operates on just two GPUs, significantly reducing computational costs while maintaining high performance.
- With 111 billion parameters, the model is optimized for enterprise-scale applications that require extensive text processing.
- The model supports a 256K context length, enabling it to process longer enterprise documents more effectively than competing models.
- Command A is trained on 23 languages, ensuring high accuracy and contextual relevance for global businesses.
- It achieves 156 tokens per second, 1.75x higher than GPT-4o and 2.4x higher than DeepSeek-V3.
- The model consistently outperforms competitors in real-world enterprise evaluations, excelling in SQL, agentic, and tool-based tasks.
- Advanced RAG capabilities with verifiable citations make it highly suitable for enterprise information retrieval applications.
- Private deployments of Command A can be up to 50% cheaper than API-based models.
- The model includes enterprise-grade security features, ensuring safe handling of sensitive business data.
- Demonstrates high proficiency in regional dialects, making it ideal for businesses operating in linguistically diverse regions.
Check out the Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
The post Cohere Released Command A: A 111B Parameter AI Model with 256K Context Length, 23-Language Support, and 50% Cost Reduction for Enterprises appeared first on MarkTechPost.

