



Large Language Models (LLMs) have shown remarkable capabilities across diverse natural language processing tasks, from generating text to contextual reasoning. However, their efficiency is often hampered by the quadratic complexity of the self-attention mechanism. This challenge becomes particularly pronounced with longer input sequences, where computational and memory demands grow significantly. Traditional methods that modify self-attention often render them incompatible with pre-trained models, while others focus on optimizing key-value (KV) caches, which can lead to inconsistencies between training and inference. These challenges have driven researchers to seek more efficient ways to enhance LLM performance while minimizing resource demands.
Researchers from Huawei Noah’s Ark Lab, The University of Hong Kong, KAUST, and Max Planck Institute for Intelligent Systems, Tübingen, have proposed SepLLM, a sparse attention mechanism that simplifies attention computation. SepLLM focuses on three token types: Initial Tokens, Neighboring Tokens, and Separator Tokens. Notably, separator tokens, such as commas and periods, often receive disproportionately high attention weights in LLMs. SepLLM leverages these tokens to condense segment information, reducing computational overhead while retaining essential context.

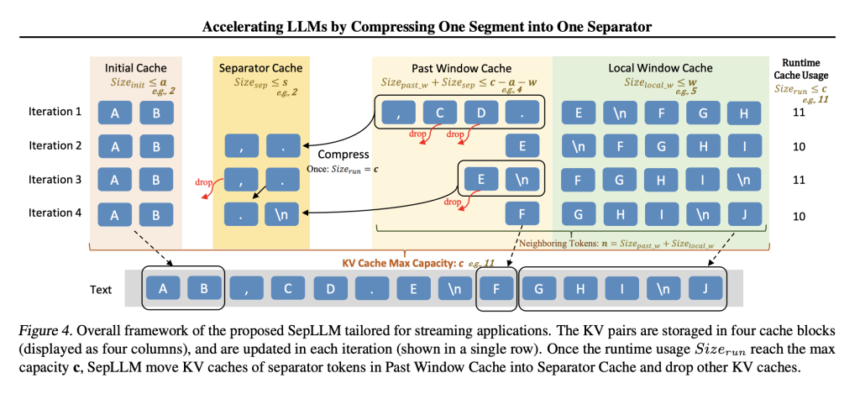
Designed to integrate seamlessly with existing models, SepLLM supports training from scratch, fine-tuning, and streaming applications. Its sparse attention mechanism prioritizes essential tokens, paving the way for efficient long-context processing.
Technical Overview and Advantages of SepLLM
1. Sparse Attention Mechanism SepLLM retains only three types of tokens:
- Initial Tokens: The first tokens in a sequence, often key to understanding context.
- Neighboring Tokens: Tokens near the current token, ensuring local coherence.
- Separator Tokens: High-frequency tokens like commas and periods that encapsulate segment-level information.
By focusing on these tokens, SepLLM reduces the number of computations required, enhancing efficiency without compromising model performance.
2. Enhanced Long-Text Processing SepLLM processes sequences exceeding four million tokens, surpassing traditional length limitations. This capability is particularly valuable for tasks like document summarization and long conversations, where maintaining context is crucial.
3. Improved Inference and Memory Efficiency SepLLM’s separator-based compression mechanism accelerates inference and reduces memory usage. For instance, on the GSM8K-CoT benchmark, SepLLM reduced KV cache usage by 50%. It also demonstrated a 28% reduction in computational costs and a 26% decrease in training time compared to standard models using the Llama-3-8B architecture.
4. Versatile Deployment SepLLM is adaptable to various deployment scenarios, offering support for:
- Integration with pre-trained models.
- Training from scratch for specialized applications.
- Fine-tuning and streaming for dynamic real-time use cases.
Experimental Results and Insights
The effectiveness of SepLLM has been validated through rigorous testing:
Training-Free Setting: Using the Llama-3-8B-Instruct model, SepLLM was tested on GSM8K-CoT and MMLU benchmarks. It matched the performance of full-attention models while reducing KV cache usage to 47%, demonstrating its ability to retain crucial context and reasoning with fewer resources.
Training from Scratch: When applied to the Pythia-160M-deduped model, SepLLM achieved faster convergence and improved task accuracy. Increasing neighboring tokens (n=128) further enhanced perplexity and downstream performance.
Post-Training: SepLLM adapted efficiently to pre-trained Pythia-1.4B-deduped models through fine-tuning, aligning with its sparse attention design. A tailored cosine learning rate scheduler ensured consistent loss reduction.
Streaming Applications: SepLLM excelled in streaming scenarios involving infinite-length inputs, such as multi-turn dialogues. On the PG19 dataset, it achieved lower perplexity and faster inference times compared to StreamingLLM, with reduced memory usage.

Conclusion
SepLLM addresses critical challenges in LLM scalability and efficiency by focusing on Initial Tokens, Neighboring Tokens, and Separator Tokens. Its sparse attention mechanism strikes a balance between computational demands and performance, making it an attractive solution for modern NLP tasks. With its ability to handle long contexts, reduce overhead, and integrate seamlessly with existing models, SepLLM provides a practical approach for advancing LLM technology.
As the need for processing extensive contexts grows, solutions like SepLLM will be pivotal in shaping the future of NLP. By optimizing computational resources while maintaining strong performance, SepLLM exemplifies a thoughtful and efficient design for next-generation language models.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post SepLLM: A Practical AI Approach to Efficient Sparse Attention in Large Language Models appeared first on MarkTechPost.


